
Zu den Herausforderungen der Softwareentwicklung im Projekt Beethovens Werkstatt: Dokumentation und Zwischenbilanz (2014–2017)
„Genetische Textkritik und Digitale Musikedition“, so heißt es im Untertitel unseres Projekts. Was aber ist die Rolle der Digitalen Musikedition in einem Grundlagenforschungsprojekt? In welchem Verhältnis stehen schnelle Entwicklung von Prototypen und Nachhaltigkeit? Welche Herausforderungen birgt die Softwareentwicklung im Bereich der Digital Humanities? Diesen und weiteren Fragen widmet sich der vorliegende Beitrag. Dabei sind kaum abschließende Antworten zu erwarten – mit diesem Thema ließen sich leicht Bücher füllen. Vielmehr soll versucht werden, am konkreten Beispiel der gegenwärtigen Entwicklung im Übergang vom ersten zum zweiten Modul des Projekts die Komplexität der notwendigen Arbeiten zu verdeutlichen und die Rolle der Softwareentwicklung im Zusammenspiel von Erkenntnisgewinn, Erkenntnismodellierung (als der zweiten, im vorliegenden Text bewusst ausgeblendeten digitalen Komponente des Projekts) sowie Erkenntnisvermittlung aufzuzeigen. Gleichzeitig dokumentiert der Text die Entwicklungsschritte im Zuge dreier Prototyp-Generationen („Fallstudie 1 – Variantendarstellung“, „Fallstudie 2 – Schreibschichten und Invarianz“, „SourceViewer“) sowie die auf diesen Erfahrungen gründenden wesentlichen architektonischen und technologischen Entscheidungen für die neu konzipierte Software „VideApp“, die mit ihrer umfassenden Funktionalität ein zentrales Ergebnis des ersten Projektmoduls ist, zugleich aber auch als modular ausbaufähige Software-Grundlage für die folgenden Projektmodule dienen kann.
Durch die in der Tradition des Projekts stehende doppelte Adressierung an Musikwissenschaftler wie auch „Editionstechniker“ versucht der folgende Text möglichst wenig spezifische Vorkenntnisse vorauszusetzen – gelegentlich mag dies nicht ganz gelungen sein. Sollten also vor allem technische Details entweder unverständlich oder unausgeführt bleiben, so ist dies als Einladung zum Dialog zu verstehen.
Ein erster Prototyp aus Beethovens Werkstatt: Variantendarstellung am Beispiel in Opus 111
Nach einer frühen Orientierungs- und Planungsphase konnte bereits zum Festakt zur Eröffnung des Projekts am 1. Dezember 2014 ein erster Prototyp vorgestellt und öffentlich zugänglich gemacht werden. Die wesentliche Neuerung dieser Machbarkeitsstudie war die enge Verknüpfung von Faksimile und Transkription, die ein unmissverständliches Sprechen über genetische Prozesse im Manuskript erlaubt – einzelne Noten oder ganze Textschichten lassen sich im Faksimile gezielt hervorheben und können so auch bei mehrfacher Überschreibung zweifelsfrei benannt und referenziert werden. Dieses „deiktische Prinzip“, also die Hinwendung zu einem direkten „Zeigen“ im Manuskript anstelle eines verbalen Umschreibens, ist die wesentliche methodische Errungenschaft des ersten Projektmoduls.
Der Ende 2014 veröffentlichte erste Prototyp erlaubte bereits eine enge Verzahnung von Faksimile und Transkription. Sichtbar ist aber auch, wie eingeschränkt die Satzqualität der aus den MEI-Codierungen erstellten Transkriptionen zu dieser Zeit noch war.
Wie man auch an der Rezension des Projekts im Journal of the American Musicological Society sieht, konnte dabei allerdings nicht ausreichend deutlich gemacht werden, dass mit dem über die Webseite als „Fallstudie 1 – Variantendarstellung“ zugänglich gemachten Prototypen zur Klaviersonate Opus 111 weder eine inhaltlich abgeschlossene Edition noch ein technisch ausgereiftes Produkt vorgelegt werden sollte. Vielmehr handelte es sich um eine an zwei Manuskriptseiten arbeitende Fallstudie, die die technische Umsetzbarkeit der deiktischen Verknüpfung von Faksimile und Transkription durch eine möglichst „leichtgewichtige“ Software demonstrieren sollte. Aus diesem Grund wurde ganz bewusst auf den Einsatz der Edirom-Software, die u. a. für Freischütz Digital, aber auch viele andere digitale Editionsprojekte der letzten Jahre genutzt wurde, verzichtet. Diese Software (die ihrerseits nach den üblichen Kriterien kaum als „marktreifes“ Produkt ohne projektspezifischen Anpassungsbedarf zu verstehen ist), trifft viele Vorannahmen zur Konzeption einer digitalen Ausgabe, die so nicht oder nur sehr bedingt auf die Fragestellungen von Beethovens Werkstatt zutreffen – gerade in den ersten Fallstudien des Projekts ging es zunächst nicht um die Kollation mehrerer Notentexte, mit der einer der wesentlichen Vorzüge dieser Software verbunden ist. Gleichzeitig macht es die monolithische Struktur der in ExtJS entwickelten Edirom Online sehr zeitaufwendig, dort die für die spezifischen Fragestellungen des Projekts nötigen Erweiterungen und Ergänzungen einzuarbeiten.
Zur Technologie des ersten Prototypen
Stattdessen wurde eine neue, stark fokussierte Anwendung als eXist-App entwickelt. Dabei handelt es sich um abgeschlossene Software-Pakete, die in einer eXist-Datenbank installiert und von dieser u. a. als Web-Anwendung an den Client (i. d. R. der Internet-Browser des Benutzers) ausgeliefert werden. Dieser Aufbau bot sich an, da sämtliche Daten des Projekts in XML vorliegen: Sowohl das für die Codierung der Notentexte und sämtlicher Metadaten genutzte MEI als auch das zum Erfassen der einzelnen Zeichen im Faksimile eingesetzte SVG basieren auf XML.
Zum Technology Stack dieser ersten Anwendung, also den genutzten Programmiersprachen, Software-Komponenten und Programmbibliotheken, gehört darüber hinaus serverseitig XQuery als Abfragesprache der Datenbank. Clientseitig nutzt die Software neben HTML (einer Auszeichnungssprache, mit der Texte, Bilder, Links etc. so beschrieben werden, dass ein Browser sie anzeigen kann) auch Javascript (welches die nötige Programmlogik ermöglicht, um aus statischen Internetseiten interaktive Web-Anwendungen zu entwickeln). Dabei kommen nur wenige zusätzliche Javascript–Bibliotheken zum Einsatz: Mit Leaflet werden die als Bildkacheln vorliegenden Faksimiles in der jeweils benötigten Auflösung zusammengefügt und angezeigt. Auch die Interaktion mit den Faksimiles (Vergrößern / Verkleinern sowie ein Verschieben des Ausschnitts) wird von Leaflet bereitgestellt. Die Einblendungen der Textschichten mussten allerdings als Erweiterung zu Leaflet projektseitig entwickelt werden.
Neben Leaflet ist vor allem der Einsatz von Verovio von herausragender Bedeutung. Dieses von Laurent Pugin (RISM Schweiz) entwickelte Programm erlaubt es, MEI-codierte Notentexte wieder als solche, das heißt als Notengraphik darzustellen. Diese Umsetzung wird als Rendering bezeichnet. Dabei können nur die reinen Notentexte angezeigt werden, nicht aber die zusätzlichen, in MEI hinterlegten Prozess-Informationen zu Streichungen oder Überschreibungen. Daher müssen diese Daten serverseitig mit XSLT (einer Programmiersprache zur Transformation von XML-Daten) so vorprozessiert werden, dass die einzelnen resultierenden Varianten mit Verovio dargestellt werden können.
An dieser Stelle sei auch darauf verwiesen, dass Verovio, dessen Notenbild aktuell nur noch wenig Wünsche offen lässt, in der Ende 2014 eingesetzten Version beispielsweise noch nicht in der Lage war, Akkorde darzustellen, so dass diese über Umwege und nur in graphisch sehr unbefriedigender Weise angezeigt werden konnten. Dabei handelte es sich nicht um ein grundsätzliches Problem, sondern nur um eine temporäre technische Einschränkung, die ohne Änderung der Daten allein durch Weiterentwicklung der genutzten „Drittbibliotheken“ zu beheben ist – und im beschriebenen Fall bereits in der folgenden Version von Verovio innerhalb weniger Monate behoben werden konnte. Die Frage, ob solche Aktualisierungen in die bestehende Software, hier also den ersten Prototyp zu Opus 111, bei Verfügbarkeit unmittelbar eingepflegt werden sollten, lässt sich in unterschiedlicher Weise beantworten. Natürlich wäre es einerseits legitim und schön, solche technischen Einschränkungen nachträglich zu beheben. Andererseits kann mit diesen Wartungsarbeiten ein nicht unerheblicher Aufwand verbunden sein, insbesondere, wenn wie im vorliegenden Fall, relativ komplexe „Workarounds“ entwickelt wurden, um die Auswirkungen der Einschränkung zu kaschieren, die dann aber mit der korrigierten Software nicht kompatibel sind und ihrerseits wieder behoben werden müssen. Aus dieser Abwägung heraus hat sich Beethovens Werkstatt in der konkreten Situation dazu entschlossen, den Prototypen in seiner veröffentlichten Version zu belassen. So wird der Entwicklungsstand zum Zeitpunkt der Veröffentlichung dokumentiert und damit der Projektverlauf durch den Vergleich mehrerer Prototypen und deren Entwicklungsschritte nachvollziehbar. Zudem würde das Beheben derartiger Probleme bei inhaltlich bereits abgeschlossenen Fallstudien beständig Entwicklerkapazitäten binden, die dann an anderer Stelle für die Entwicklung neuerer Werkzeuge fehlen. Da gerade diese Entwicklerkapazitäten in Beethovens Werkstatt recht knapp bemessen sind – basierend auf den Stellenbeschreibungen investiert das Projekt nicht einmal ein Zehntel der Arbeitszeit in Softwareentwicklung – werden daher die Korrekturen an den bestehenden und veröffentlichten Werkzeugen zunächst aus pragmatischen Gründen auf das zwingend Nötige beschränkt.
Trotz der genannten Schwierigkeiten konnte mit dem ersten Prototypen eine erstaunlich schlanke Anwendung vorgelegt werden – der Javascript-Anteil des Programms beläuft sich auf etwa 1.000 Zeilen Quelltext (inkl. Dokumentation), für XQueries und XSLTs dürfte insgesamt etwa der gleiche Umfang hinzukommen. Zum Vergleich: der Quelltext der Edirom-Software umfasst (inkl. des erwähnten ExtJS-Frameworks) mehrere 100.000 Zeilen Code, Verovio als eine der wichtigsten Drittbibliothken kommt auf etwa 100.000 Zeilen Quelltext.
Erweiterung der Software für Opus 59, 3: Varianz, Invarianz und Schreibschichten
Prototyp 2 mit Fallstudie aus Opus 59,3
Nach den Arbeiten an Opus 111 wurde als nächste Fallstudie eine durch die Überlagerung von vier Varianten besonders komplexe Stelle („Textnarbe“) in Beethovens Arbeitsmanuskript zum Streichquartett Opus 59, 3 in den Blick genommen. Im ersten Prototyp wurden die einzelnen Varianten relativ „nüchtern“ dargestellt: Im Faksimile können die jeweils eine Variante konstituierenden Zeichen in einer gemeinsamen Farbe hervorgehoben werden; parallel werden sie mit Verovio auch als Transkription (als Cleartexte ohne farbliche Markierung) angezeigt. Im Sinne einer ausgeprägteren Kontextualisierung der Varianten wurde anhand der charakteristischen Textnarbe in Opus 59, 3 das philologische Konzept der Invarianz entwickelt. Damit wird zum eigentlichen Text der jeweiligen Variante durch Einfärbung gezeigt, welche Textsegmente aus früheren Varianten an die aktuell vorliegende unverändert „vererbt“ werden. Auch die Definition des Begriffs Schreibschicht wurde wesentlich überarbeitet, um zu präziseren Visualisierungen von Schreibprozessen gelangen zu können.
Alle drei Konzepte, also Varianz und Invarianz (als nunmehr vor allem textuell aufgefasste Phänomene) sowie die Abfolge der Schreibschichten (als die rein skripturale Seite der Medaille), sollten nun sowohl im Faksimile als auch in den Transkriptionen der vier Varianten durch Einfärbungen der entsprechenden Notentexte umgesetzt werden. Gleichzeitig sollte die Software einen Mechanismus zur Internationalisierung erhalten, um eine angepasste Benutzeroberfläche für verschiedene Sprachen anbieten zu können.
Konzeptionelle und technologische Grenzen
Sowohl die Einfärbungen als auch die Internationalisierung konnte mit dem für Prototyp 1 genutzten Technology Stack in die bestehende Software integriert werden. Durch den technischen Aufbau der eXist-App war es möglich, die Internationalisierung mit nur einer einzigen Sprachdatei umzusetzen, die sowohl für serverseitige als auch clientseitige Lokalisierungen genutzt wird. Dieses Konzept des DRY (Don‘t repeat yourself) ist ein wesentliches Prinzip der Softwareentwicklung und soll verhindern, durch unvollständig ausgeführte Änderungen schwer nachvollziehbare und zu behebende Inkonsistenzen zu riskieren.
(Deutlichere) Probleme traten bei der Implementierung der neuen Einfärbungsmodi für Schreibschichten und Invarianz zutage. In der ursprünglichen Software waren diese konzeptionell nicht vorgesehen, es gab keine entsprechenden Strukturen, die als Grundlage hätten genutzt werden können. Stattdessen mussten nun bestehende Funktionen erweitert, umgeschrieben oder auch teilweise umgangen werden. Die vormals sehr klare und übersichtliche Struktur der Software wurde durch diese Erweiterungen erheblich beeinträchtigt, und es war klar, dass damit die strukturellen Möglichkeiten der vorhandenen Software-Architektur weitgehend ausgeschöpft waren.
Aus inhaltlicher Sicht wurde in der Benutzung der als Prototyp „Fallstudie 2 – Schreibschichten und Invarianz“ verfügbaren Software deutlich, dass die Umsetzung der Konzepte von Einfärbung sowohl von Schreibschichten, Invarianz und Varianten in der gewählten Form für den Benutzer nur schwer nachvollziehbar war: Der Bedeutungsträger „Farbe“ wurde sowohl im Faksimile als auch in den Transkriptionen für sehr unterschiedliche Informationen genutzt, wobei sogar die gleiche Farbe je nach Darstellungsmodus mit unterschiedlichen Aussagen verbunden war. Gleichzeitig wurden die hinter diesen Modi stehenden philologischen Konzepte zumindest im Kontext des Prototyps nicht ausreichend erklärt, so dass der Benutzer die jeweilige Einfärbung allzu leicht verwechseln konnte. Letztlich versuchte dieser Prototyp, zu vieles „auf zu engem Raum“ zu vermitteln – die einzelnen Funktionen ließen sich nicht hinreichend unterscheiden. Ein grundsätzlich denkbarer und einfacher Rückgriff auf weitere Farben erwies sich als nicht überzeugend: Einerseits blieb es dabei beim Medium „Farbe“, das genutzt wird, um unterschiedliche Arten von Information zu vermitteln, andererseits ist die Anzahl von Farben, die sowohl hinreichend erkenn- als auch unterscheidbar sind – zumal als farbliche Überlagerung in einem bereits von sich aus „bunten“ Digitalisat – erstaunlich gering (wie die späteren Arbeiten an Opus 75, 2 zeigen sollten).
Auf dem Weg zu einer modularen Software-Architektur: Ein multifunktionaler SourceViewer für Opus 75, 2, Opus 93 und WoO 32
Während die technische Umsetzung der beiden ersten Fallstudien sequentiell erfolgte, entschloss sich das Projekt, an dieser Stelle auf eine parallele Betrachtung der im ersten Projektmodul noch geplanten Fallstudien aus Opus 75, 2 (Klavierlied Neue Liebe, neues Leben), Opus 93 (8. Sinfonie) sowie WoO 32 (Duett mit zwei obligaten Augengläsern für Bratsche und Cello) zu wechseln. Auslöser dieser Entscheidung war die beschriebene Beobachtung, dass die vorhandene Infrastruktur kaum geeignet schien, weitere inhaltlich-methodische Neukonzeptionen und die daraus resultierenden technischen Änderungen in hinreichend stabiler und nachhaltiger Weise umsetzen zu können. Stattdessen sollten durch die Auseinandersetzung mit den drei genannten Werken und ihrer jeweiligen Codierung die für den Rest des ersten Projektmoduls zu erwartenden Anforderungen gesammelt werden, um diese dann in einer von vornherein auf die gesamte Bandbreite der dafür benötigten Funktionen angelegten Software-Architektur umsetzen zu können. So sollten „Reibungsverluste“ durch spätere Umarbeitungen und Anpassungen möglichst vermieden und die vorhandenen Entwicklerkapazitäten bestmöglich genutzt werden.
Dementsprechend wurden die für Opus 75, 2 bzw. 93 benötigten Funktionen als separate Web-Anwendungen mit möglichst einfachem Unterbau entworfen, um diese später als einzelne Komponenten eines größeren Systems – des späteren „SourceViewers“ – zusammenfügen zu können. Auf diese Weise sollten zunächst völlig getrennte Werkzeuge jeweils eine eindeutige „Sicht“ auf die Daten bieten, bei der sich auch die Benutzeroberfläche auf das unbedingt nötige beschränkt und damit einen möglichst intuitiven Zugang erlaubt.
Herausforderung Mehrdeutigkeit
In diesem Zuge wurde zunächst für eine Stelle aus Opus 75, 2 das Konzept der Invarianz präzisiert und durch einen neuen Prototyp umgesetzt. Hierbei ergab sich aus der gewählten Textnarbe wiederum eine neue Herausforderung: Während in den früheren Fallstudien eine klare Abfolge der einzelnen enthaltenen Varianten identifiziert werden konnte, gab es in Opus 75, 2 durch den größer gewählten Textausschnitt im Projekt erstmals den Fall, dass die genaue Variantenabfolge nicht eindeutig festgelegt werden konnte. Auf Seite der MEI-Codierungen wurde dafür eine ebenso einfache wie elegante Lösung gefunden. Dabei wird nicht mehr eine durchgängige feste Reihenfolge der einzelnen Schreiboperationen angenommen, sondern diese werden in der philologisch begründbaren Genauigkeit in Relation zueinander gesetzt. Als Beispiel: Die (fiktive) Operation A wurde (aus editorischer Sicht) in jedem Fall zeitlich vor Operation B ausgeführt, dazwischen könnten aber noch Operationen X, Y oder Z ausgeführt worden sein, ohne dass hier eine Festlegung möglich wäre. Mit einer solchen Codierung lässt sich sehr genau der editorische Kenntnisstand (inkl. seiner möglichen Unschärfe) modellieren.
Daraus ergibt sich allerdings ein gravierendes Problem für die technische Umsetzung: Konnten die bisherigen Fallstudien einfach alle Varianten in einer festen Reihenfolge auflisten, ergeben sich bei einer unklaren Reihung der Schreiboperationen unterschiedliche Varianten, von denen zwar nur eine der tatsächlichen Schreibchronologie entsprechen kann, die aber allesamt als zumindest plausibel zu gelten haben und daher dem Benutzer zur eigenen Überprüfung des Sachverhalts vorgelegt werden sollten. Das Bereitstellen sämtlicher Kombinationsmöglichkeiten scheidet dabei angesichts von insgesamt siebzehn Varianten im Falle von Opus 75, 2 von vornherein aus – auch wenn nur einige Teilbereiche der Variantenabfolge unklar sind, ergeben sich in vergleichbaren Beispielen leicht mehrere hundert oder gar tausende Kombinationen, die für den Benutzer weder erfass- noch nachvollziehbar wären. Stattdessen konnte im Projekt ein Benutzerinterface entwickelt werden, welches es dem Benutzer erlaubt, einzelne Schreibschichten im Rahmen der vom Editor vorgegebenen Möglichkeiten zu (de)aktivieren, und den daraus resultierenden Notentext (Textzustand) zu betrachten. Um auch weiterhin einen Vergleich zweier Textzustände zu erlauben, wurde diese Ansicht gedoppelt, so dass gezielt verschiedene „Konfigurationen“ des Notentextes gegenübergestellt werden konnten.
Text vs. Skriptur
Dieses Benutzerinterface, welches dem Nutzer auf interaktive Weise gerade auch die Erfassung der mit unklaren Variantenreihenfolgen einhergehenden Kombinationen und Textbewegungen ermöglicht, wurde zunächst bei der Invarianz-Darstellung implementiert. Das Konzept der Invarianz stellt eine analytische Betrachtung der Text-Entwicklung dar, die unabhängig von den nötigen Schreiboperationen im Dokument allein auf der Ebene der aus diesen Operationen resultierenden Variantentexte funktioniert. Die farbliche Markierung der Invarianz wurde daher konsequent auf die Einfärbung der Transkriptionen beschränkt, und nicht mehr, wie noch bei Opus 59, 3, auch im Faksimile angeboten. (Und umgekehrt wurden die farblichen Markierungen im Faksimile für skripturale Phänomene reserviert.)
Invariance Visualizer (inViz) von 2015. Zu sehen ist die Benutzerführung auf der rechten Seite, mit der einzelne Varianten unter Berücksichtigung notwendiger früherer Varianten ausgewählt werden können.
Der Verzicht auf eine Invarianz-Einfärbung der Faksimiles ist damit eine methodische Präzisierung – erst durch die Begrenzung auf die Abstraktion einer „neutralen“, nicht-diplomatischen Transkription (Cleartext), die dem Konzept der Invarianz theoretisch sehr viel präziser entspricht und es zudem technisch besser darstellbar und für den Benutzer deutlich leichter nachvollziehbar macht, wird die Invarianz-Darstellung zum wirklich hilfreichen Werkzeug bei der Erschließung der Textgenese. Dieser unter dem Namen „Invariance Visualizer“ (kurz: InViz) entwickelte „Proof of Concept“ sollte nach Untersuchung aller Anforderungen der verschiedenen Fallstudien in dann ausgereifter Form in die neu zu entwickelnde Gesamtanwendung SourceViewer integriert werden.
Mit ähnlichen Argumenten wie bei der Fokussierung der Invarianz, allerdings unter umgekehrten Vorzeichen, wurde die mit Opus 59, 3 eingeführte Einfärbung der Schreibschichten überarbeitet. Operiert der Begriff der Invarianz auf der Textebene – und damit nur in den Transkriptionen, so erschließt sich eine Einfärbung der Schreibschichten ausschließlich im Kontext des Dokuments, also anhand des Faksimiles. Bei der Umsetzung der Schreibschichteneinfärbung für Opus 75, 2 wurde das Konzept nochmals deutlich ausgeweitet: Anstatt die jeweiligen Schreibschichten nur im Faksimile hervorzuheben, wurde eine vollständige Rekonstruktion der Niederschrift des Faksimiles entwickelt. Dazu wurden neben den bereits vorhandenen Notenzeichen und sonstigen Schreibspuren auch die Notenlinien sowie die Seitenumrisse als sogenannte SVG-Formen codiert. Damit kann in diesem „Reconstruction Visualizer“ (kurz: ReViz) zunächst die „leere“ Notenseite, wie sie Beethoven zu Beginn seiner Arbeiten vorgefunden hat, dargestellt werden. Aktiviert der Benutzer nun mit dem bereits aus dem Invariance Visualizer bekannten Benutzerinterface einzelne Schreibschichten, werden die zugehörigen Zeichen auf diese leere Seite aufgebracht.
Damit kann die Genese des Manuskripts nicht nur durch Einfärbungen einzelner Zustände analysiert, sondern unmittelbar in ihrer Prozessualität sichtbar gemacht werden. Auch hier lassen sich die aus editorischer Sicht nicht auflösbaren Unklarheiten der chronologischen Abfolge wieder offen vermitteln, so dass der Benutzer selbst die verschiedenen Reihungen sichten und eigenständig ihre Plausibilität hinterfragen kann. Gerade in der Gegenüberstellung von Invarianz- und Rekonstruktionsansicht lässt sich so sehr eindrücklich nachvollziehen, welche textuellen Entscheidungen Beethoven im Angesicht verschiedener Schriftbilder getroffen hat. Die digitale Musikedition ermöglicht es damit, den komplexen Vorgang Textgenese ohne raumgreifende (und dennoch kaum jemals eindeutige) verbale Beschreibungen relativ leicht nachvollziehbar und im Wortsinne „offensichtlich“ zu machen.
Reconstruction Visualizer (reViz) von 2015. Zu sehen ist, dass über das gleiche Benutzerinterface wie bei inViz einzelne Textschichten in chronologisch plausibler Reihenfolge zu einer Rekonstruktion des Faksimiles zusammengefügt werden können. Dieses steht über einen Schieberegler, der die Transparenz der Rekonstruktion steuert, immer im Hintergrund zur Kontrolle zur Verfügung.
Um an dieser Stelle nochmals auf das Argument der „Überfrachtung“ des Bedeutungsträgers Farbe als Kritikpunkt an Prototyp 2 zurückzukommen: Für die genannten 17 Varianten der Fallstudie aus Op.75, 2 müssen bereits für die Invarianz-Einfärbung ebenso viele verschiedene Farben genutzt werden. Trotz umfangreicher Bemühungen konnte dafür kein hinreichend eindeutiges Farbschema gefunden werden, welches eine zweifelsfreie Zuordnung von Farbe zu Variante erlauben würde. „Farbe“ ist damit ein zwar sehr wirksames Mittel zur Kennzeichnung bzw. Überlagerung weiterer Informationen, in seinen Differenzierungsmöglichkeiten aber sehr beschränkt.
Rekonstruktion dokumentübergreifender textgenetischer Prozesse und besondere Herausforderungen für die Datenmodellierung
Während für die Fallstudie aus Opus 93 – den verschiedenen Fassungen zum Abschluss des ersten Satzes von Beethovens 8. Sinfonie – keine Invarianz-Darstellung geplant wurde, stellte die Rekonstruktion dieses Beispiels eine qualitativ neue Herausforderung dar, mussten doch erstmals mehrere Manuskripte berücksichtigt werden. Damit nicht genug – zusätzlich zu den Schreiboperationen innerhalb eines Manuskriptes mussten hier auch Änderungen am Textträger selbst berücksichtigt werden, da Beethoven im Zuge seiner Arbeiten ein Blatt des heute in Berlin liegenden Autographs heraustrennte. Außerdem wurde in einer Kopistenabschrift ein Teil des Textes überklebt, und diese Überklebung mit einer späteren Textfassung der Paukenstimme beschrieben. Damit ändert sich in diesem Beispiel nicht nur der Inhalt der Seite – Schriftzeichen werden nach und nach ergänzt – sondern die Seitenanordnung und -gestalt selbst wird durch die Kompositions- und Überarbeitungsprozesse verändert. Demgegenüber waren die in diesem Beispiel wesentlich deutlicher zu Tage tretenden Unklarheiten bzw. Ungenauigkeiten in der chronologischen Abfolge der verschiedenen Schreiboperationen deutlich leichter zu handhaben und konnten mit den anhand der vorhergehenden Fallstudien entwickelten Modelle umgesetzt werden. Für die hier erstmals auftretenden Änderungen an den Textträgern selbst war allerdings zunächst eine Erweiterung von MEI nötig, um überhaupt eine angemessene Codierung zu ermöglichen. Die dafür nötigen Datenmodelle wurden in Zusammenarbeit mit dem Projekt zum Detmolder Hoftheater entwickelt, da auch dort entsprechende Eingriffe in den zu erfassenden Materialien beobachtet wurden, ohne diese allerdings aus einer textgenetischen Perspektive auch inhaltlich zu erschließen.
Proof of Concept zur Rekonstruktionsansicht mit mehreren Quellen anhand Op. 93 (2016). Durch unterschiedliche Auflösungen der zugrunde liegenden Digitalisate kann hier das eigentliche Faksimile nicht mehr angezeigt werden.
Aber auch in diesem Fall stellte die graphische Umsetzung dieser Codierungen die größere Herausforderung dar: Die Rekonstruktionsansicht wurde ursprünglich basierend auf der regulären Faksimile-Ansicht entworfen und dementsprechend mit dem schon im ersten Prototypen zu Opus 111 genutzten Leaflet umgesetzt. Bei Leaflet handelt es sich eigentlich um eine Javascript–Bibliothek zur Anzeige von Landkarten und anderen Geodaten, ähnlich dem bekannten Google Maps. Ein Teil der notwendigen Anpassungen war daher von Beginn an die wechselseitige Umrechnung von Geokoordinaten in Bildpositionen – intern arbeitet Leaflet auch bei den Faksimiles von Beethovens Handschriften mit Längen- und Breitengraden ( – glücklicherweise bietet es von Haus aus einen Modus, um die Erdkrümmung außer Acht zu lassen). Allerdings ergab sich gerade durch die gleichzeitige Anzeige mehrerer Quellen ein gravierendes Problem: Diese Quellen lagen nicht alle in der gleichen Auflösung vor. Damit wäre die aus dem Berliner Autograph entfernte und jetzt im Beethoven-Haus Bonn liegende Seite, trotz nahezu identischer physikalischer Abmessungen, in ungefähr doppelter Größe dargestellt worden. Ein Verkleinern der höher aufgelösten Bilddateien schied als Möglichkeit aus, da so die Qualität der Faksimiles immer auf das schlechteste aller Digitalisate begrenzt würde – ein mit der deiktischen Herangehensweise des Projekts nicht vereinbarer Kompromiss.
Weiterhin wurde beabsichtigt, das „Herausreißen“ dieses Blattes anders als die unmittelbar erscheinenden Textschichten nicht als übergangslosen Wechsel der Position darzustellen, sondern als Bewegung zu animieren, um den Vorgang unmittelbar nachvollziehbar zu machen. Übersetzt auf die Funktionen einer Landkarten-Bibliothek ergibt sich daraus allerdings der Wunsch, quasi eine Kontinentaldrift im extremen Zeitraffer zu simulieren. Damit war klar, dass die gewünschten Funktionalitäten zumindest unter Berücksichtigung der Faksimiles nicht mit vertretbarem Aufwand zu entwickeln waren. Allerdings bietet Leaflet sogenannte Overlays, also Überblendungen, die auch schon für die Hervorhebung der einzelnen Textschichten im Faksimile mittels SVG genutzt wurden. Diese Overlays lassen sich deutlich leichter und freier manipulieren als die eigentlichen Bilddateien. Aus diesen Überlegungen heraus wurden die SVG-Dateien der leeren Seiten wie auch der darauf liegenden Notenzeichen anhand der Originalabmessungen in den gleichen Maßstab skaliert und konnten somit in einem realistischen Größenverhältnis zugänglich gemacht werden. Auch die gewünschte Animation des Heraustrennens ließ sich mittels Overlays umsetzen. Im Ergebnis konnte so auch für Opus 93 eine überzeugende und intuitive Rekonstruktion der verschiedenen Textzustände umgesetzt werden. Dabei war allerdings klar, dass diese Lösung nicht um einen direkten Zugriff auf die Faksimiles erweitert werden könnte – eine deutliche Einschränkung. Den ursprünglichen Anforderungen entsprach Leaflet sehr wohl: Es bietet eine hinreichend schnelle Darstellung einzelner Quellen, ermöglicht die Überblendung mit SVG-Nachzeichnungen der einzelnen Schriftzeichen, hat gute Navigationsmöglichkeiten sowohl in der Benutzeroberfläche als auch durch interne Programmaufrufe, und besticht überdies durch eine sehr übersichtliche und umfassende Dokumentation, welche die Integration in die Projektentwicklungen begünstigt. Durch die sich erweiternden Anforderungen traten allerdings nennenswerte Einschränkungen zu Tage, die so im Vorfeld nicht sichtbar waren, und die im weiteren Projektverlauf auch zu einer Neuausrichtung führten (s. u.).
Methodische und technische Probleme der Variantentranskription und Variantenkontextualisierung
Auch die letzte Fallstudie des ersten Projektmoduls, Beethovens Duett mit zwei obligaten Augengläsern WoO 32, brachte nochmals neue Anforderungen mit sich, die in diesem Fall vor allem die Benutzerführung betrafen. Anders als in den vorhergehenden Beispielen sollte hierbei nicht eine einzelne Textnarbe in den Blick genommen werden, sondern sämtliche Textnarben dieses sechsseitigen Manuskripts. Dazu wurden knapp 50 Textnarben unterschiedlicher Größe identifiziert und per MEI-Codierung erfasst. Größtenteils handelt es sich dabei um sehr überschaubare Änderungen am Text – die Sofortkorrektur einer einzelnen „verschriebenen“ Note, das Aufteilen einer Sechzehntelnote in zwei Zweiunddreißigstel usw. Allerdings gibt es auch zwei größere, im Umfang durchaus mit den früheren Fallstudien des ersten Projektmoduls vergleichbare Textnarben mit sechs bzw. sieben erkennbaren Textzuständen.
Die spezifische Herausforderung von WoO 32 war, diese unterschiedlich dimensionierten Textnarben in angemessener Weise zu vermitteln. Zunächst musste ein Mechanismus gefunden werden, um überhaupt verschiedene Textnarben betrachten zu können – bis dato waren die einzelnen Varianten bzw. Schreibschichten einer Textnarbe die einzige „Navigationseinheit“. Gleichzeitig stellt die Anzeige der einzelnen Varianten eine erhebliche Anforderung an die Benutzerführung: Stellenweise muss – folgt man den anhand der vorhergehenden Fallstudien getroffenen Entscheidungen – lediglich eine einzelne Note gezeigt werden.
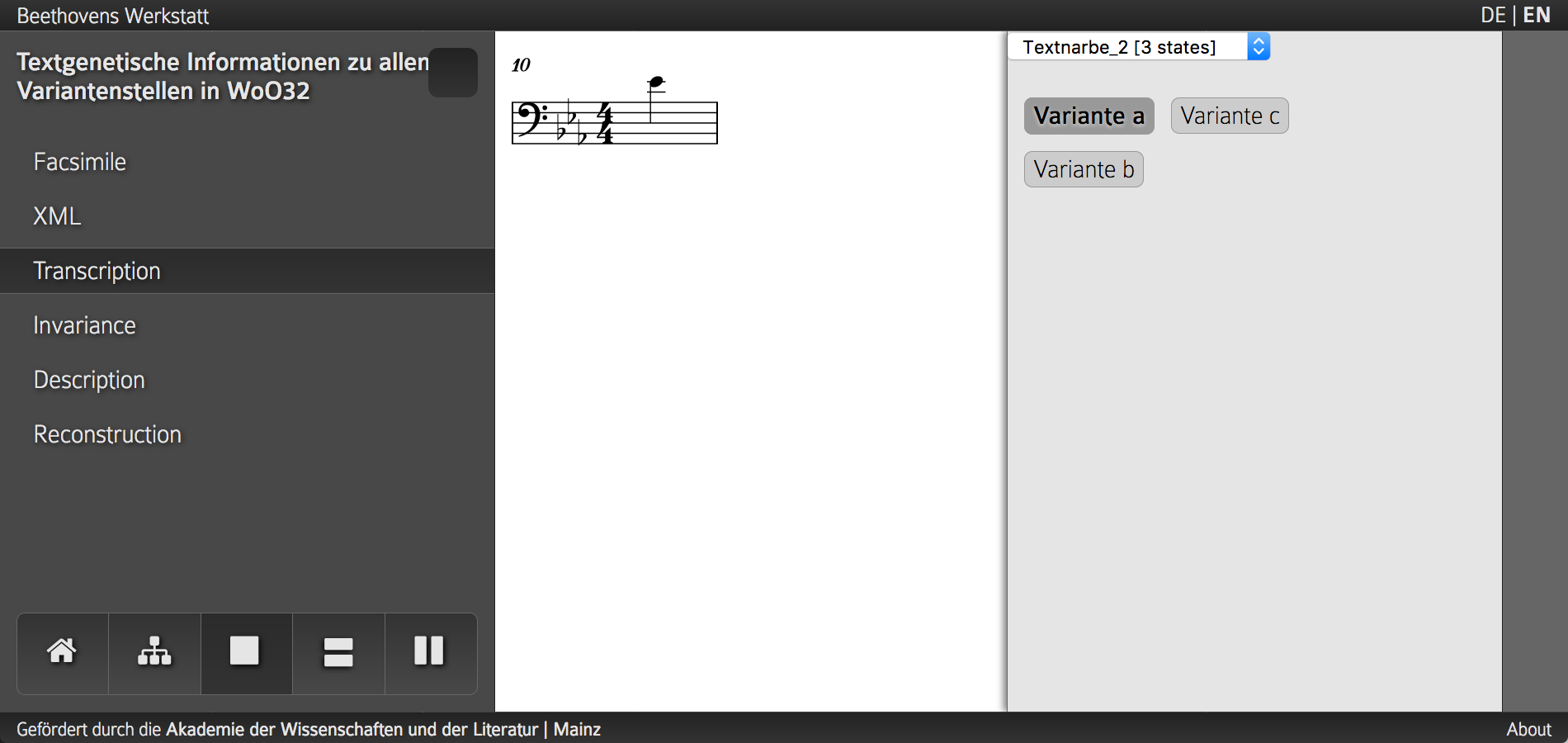
Anzeige einer aus einer einzelnen Note bestehenden Variante innerhalb von WoO 32. Es wird deutlich, dass diese Ansicht durch den gemäß den bisherigen Richtlinien fehlenden Kontext wenig Aussagekraft besitzt. Softwareseitig handelt es sich um eine frühe Version der VideApp.
Da die Varianten bislang als Transkription ohne den Kontext dargestellt werden, ergibt sich hier zwangsläufig eine Ansicht von sehr begrenzter Aussagekraft, die dem Benutzer letztlich unverständlich bleiben muss. Eine Erweiterung des sichtbaren Ausschnitts, um auch den Kontext zu integrieren, ist aber von inhaltlicher Seite alles andere als trivial und oft nicht möglich: Im Falle einer Sofortkorrektur gibt es für die verworfene(n) Variante(n) nur „auf der linken Seite“ einen Anschluss an den Kontext, der Notentext war zu diesem Zeitpunkt aber noch nicht über die erst später als solches erkennbare „Störstelle“ hinweg weitergeführt. Entsprechend müssen nur die Noten „davor“ angezeigt werden. Bei späteren Korrekturen dagegen ist die Textnarbe beidseitig kontextintegriert, d. h. auch der nachfolgende Text gehört zum Kontext der einzelnen Varianten. Problematisch wird es nun, wenn Sofortkorrekturen nicht sicher als solche erkannt werden können, oder wenn sich skriptural benachbarte Überarbeitungsprozesse, für die eine detaillierte Chronologie aller enthaltenen Varianten nicht bestimmt werden kann, überlagern. Letztlich handelt es sich hier um ein methodisches Problem, das allerdings erst in der technischen Umsetzung manifest wird, und für das bislang noch keine überzeugende Lösung gefunden werden konnte. Im Rahmen der aktuellen Entwicklungen wird für dieses Problem eine veränderte Herangehensweise erprobt; inwiefern diese neue Darstellungsform überzeugender (und damit gleichzeitig nachhaltiger) ist, wird sich erst im Gebrauch erweisen.
Aktuelle Anzeige einzelner Varianten einer Textnarbe in der VideApp (Stand: April 2017). Im Gegensatz zur früheren Version wird hier immer der letztgültige Notentext des Werks als Referenz im unteren Bereich angezeigt, so dass die einzelnen Varianten nicht mehr kontextfrei betrachtet werden müssen. Zu sehen ist auch, dass die vormals vertikale Anordnung der chronologisch aufeinander folgenden Varianten hier durch ein horizontales Layout ersetzt wurde, das sich am verbreiteten Konzept eines „Zeitstrahls“ orientiert.
Zum Aufbau der VideApp als nachhaltiges System
In der Zusammenschau der beschriebenen Herausforderungen wurde deutlich, dass eine einfache Kombination der prototypisch skizzierten Werkzeuge in einer geplanten, auf den ersten beiden Prototypen zumindest teilweise aufsetzenden und monolithisch konstruierten Gesamtanwendung namens „SourceViewer“ kaum möglich sein würde. Invariance Visualizer und Reconstruction Visualizer hatten zwar als Machbarkeitsstudie ihren Zweck zufriedenstellend erfüllt, die bereits bei Github begonnene Entwicklung einer alle Anforderungen der verschiedenen Fallstudien abdeckenden Anwendung war aber schon mit der Übertragung der Rekonstruktionsansicht auf den Fall aus Opus 93 an die oben erwähnten Grenzen gestoßen, welche die Nachhaltigkeit des vorhandenen technischen Unterbaus grundsätzlich in Frage stellten. Verbunden mit den in WoO 32 augenscheinlich gewordenen Herausforderungen an die Navigation wurde daher im Spätsommer 2016 die neuerliche Gefahr einer zu sehr auf die aktuellen Probleme fokussierten, für die anstehenden Fragestellungen des zweiten Projektmoduls nicht geeigneten Softwarearchitektur deutlich. Obwohl zu diesem Zeitpunkt die inhaltlich weitgehend abgeschlossenen Arbeiten an Opus 75, 2, Opus 93 und WoO 32 – entgegen den ursprünglichen Planungen – noch nicht mit entsprechenden Prototypen öffentlich vorgelegt waren, sondern nur projektintern als Diskussionsgrundlage und über Screenshots bzw. Screencasts für öffentliche Vorträge etc. genutzt wurden, entschied sich das Projekt angesichts der zur Verfügung stehenden Entwicklerkapazitäten und nach reiflicher Überlegung, die Arbeiten am „SourceViewer“ neu zu strukturieren und eine auch auf lange Sicht nachhaltige Architektur zu implementieren, bei der – wie ursprünglich geplant – einzelne Werkzeuge für spezifische Ansichten genutzt werden können, bei der aber gleichzeitig möglichst große Teile der Anwendung so generisch gehalten werden sollten, dass diese nicht nur für die konkret zu lösenden Aufgaben der aktuellen Fallstudien nutzbar wären, sondern auch für zukünftige Darstellungsformen und Projektmodule. Hinzu kam die Erkenntnis, dass die immer aufwendiger werdenden MEI-Codierungen mittelfristig nicht mehr manuell erstell- und wartbar sein würden, so dass auch Editor-Funktionen zur Eingabe der Daten benötigt würden.
In dieser Ausgangslage wurde daher, basierend auf den Erfahrungen von Beethovens Werkstatt, aber auch aus der Entwicklung der Edirom-Software, eine veränderte Architektur entworfen, wohlwissend, dass sich dadurch zunächst Verschiebungen im Arbeitsplan des Projekts ergeben würden. Die Zielsetzung dabei war, dass sich durch diese architektonischen Umbauten zukünftige Entwicklungen wesentlich beschleunigen lassen würden, so dass das Projekt im zweiten Projektmodul (und darüber hinaus) aufgrund der geleisteten Vorarbeiten zügiger vorankommen würde. Die aktuellen Abschlussarbeiten an der Software legen nahe, dass diese Strategie aufgeht.
Architektonische Vorüberlegungen
Ein inzwischen gängiges Konzept der Informatik stellen sogenannte Microservices dar (vgl. etwa Sam Newman: Building Microservices. Designing Fine-Grained Systems, O‘Reilly, Sebastopol 2015). Die Idee dabei ist, Anwendungen nicht mehr monolithisch, d. h. als ein komplexes Gesamtsystem, welches ohne externe Abhängigkeiten sämtliche benötigten Funktionen aus sich heraus bereitstellt, zu entwickeln, sondern unterschiedliche Funktionen in möglichst überschaubare Einheiten zu untergliedern, die ausschließlich über standardisierte Schnittstellen (sogenannte APIs, englisch für Application Programming Interface) miteinander kommunizieren, aber keine Annahmen über den internen Aufbau der anderen Projektmodule betreffen. Durch diese starke Abschirmung der einzelnen Komponenten gegeneinander sollen diese innerhalb einer Gesamtanwendung leichter austauschbar werden, und gleichzeitig durch ihre definierten Schnittstellen auch in andere Anwendungen integriert werden können. Der Name Microservices deutet dabei bereits an, dass diese Softwaremodule möglichst kleine, gerade noch inhaltlich sinnvolle und abgeschlossene Einheiten umfassen. Dadurch wird es möglich, unbefriedigende Komponenten mit minimalem Aufwand auszutauschen – so lange die definierten Schnittstellen zu den anderen Komponenten weiter eingehalten werden, kann dies ohne weitere Änderungen an der Gesamtarchitektur bzw. anderen Softwaremodulen geschehen. Dabei kann je nach Art der definierten Schnittstellen sogar die genutzte Programmiersprache geändert werden.
Dieses Konzept der Microservices bietet sich damit ideal für ein Projekt wie Beethovens Werkstatt an: Mit Faksimile-Ansicht, Transkriptions-, Invarianz- oder auch XML-Ansicht lassen sich unmittelbar potentielle Module identifizieren, die weitgehend unabhängig voneinander operieren können. Gleichzeitig können zukünftige Darstellungsformen und Visualisierungen leicht(er) in die Grundarchitektur eingefügt werden, ohne dort massive Umbauten zu erfordern. Dementsprechend entschloss sich Beethovens Werkstatt, die projektinterne Softwareentwicklung auf eine solche Microservice-basierte Architektur umzustellen, auch wenn dazu alle bestehenden Komponenten aufgeteilt und gegeneinander abgeschottet werden mussten. Dieser Prozess ist zwar zunächst recht zeitintensiv sowie fehlerträchtig und verlangsamt damit die Entwicklung – anstatt zwei Funktionen aus unterschiedlichen Modulen direkt miteinander zu verknüpfen, muss nun immer erst eine gemeinsame Schnittstelle definiert werden. Andererseits aber kann bei zukünftigen Entwicklungen nun direkt auf diese Schnittstellen zugegriffen werden, d. h. der gesamte Programmcode wird wesentlich besser wartbar. Auch lassen sich damit künftig ggf. notwendige Umbauarbeiten auf kleine Teile der Anwendung begrenzen und damit auch mit überschaubaren Ressourcen ausführen. Für ein Projekt mit kürzerer Laufzeit wäre der architekturbedingte Mehraufwand weder zu leisten noch zu rechtfertigen; angesichts der erwarteten Laufzeit von Beethovens Werkstatt bis zum Jahr 2029 lohnt sich diese Investition aber durchaus, sorgt sie doch für eine größere Nachhaltigkeit und Nachnutzbarkeit der entwickelten Software – auch in anderen Projekten und Kontexten.
Eine Analyse der Anforderungen an die Software legte eine Aufteilung in die folgenden Module nahe:
- Faksimile-Ansicht
- Transkriptions-Ansicht
- XML-Ansicht
- eine Text-Ansicht für Quellenbeschreibungen u. Ä.
- Invarianz-Ansicht
- Rekonstruktions-Ansicht
Zu diesen inhaltlich-funktional definierten Softwaremodulen treten noch die clientseitige Rahmenanwendung, die alle anderen Module bündelt und mit einer gemeinsamen Navigation versieht, sowie eine Serverkomponente hinzu. Für die Umsetzung der anderen, oben genannten Funktionen in separate Module stellen diese beiden – Rahmenanwendung und Server – die Voraussetzung dar und wurden daher als erste Komponenten der nun „VideApp“ genannten Software in den Blick genommen.
Grundlegende Softwarekomponenten
Um größtmögliche Zukunftssicherheit zu erzielen, wurden die einzusetzenden Technologien, Softwarebibliotheken und Architekturentscheidungen gründlich recherchiert. Eine wesentliche Erkenntnis dieser Arbeitsphase ist, dass neben der regulären Arbeit im Projekt nicht ausreichend Zeit zur eigenen Weiterbildung bleibt, da die oftmals beeindruckend schnellen Fortschritte im Bereich der Webentwicklung nicht ausreichend verfolgt werden können, und so allzu leicht komplexe Probleme mit veralteten Methoden gelöst werden, für die inzwischen bequem nutzbare, neuere Ansätze existieren. Aus diesem Grund wurde entschieden, die Anwendung erst nach einer gründlichen Recherche- und Einarbeitungsphase in der aktuellen stabilen Version von Javascript, genannt Ecmascript 6 (ES6 bzw. auch ES2015), zu entwickeln. Diese Version von Javascript bringt viele neuere Funktionen mit sich, die in älteren Versionen entweder sehr umständlich manuell nachgebildet oder durch Hinzuziehen zusätzlicher Softwarebibliotheken wie JQuery oder Prototype nutzbar gemacht werden mussten. So aber konnte die Software – nach entsprechender Einarbeitung – in einer modernen, schlanken und zukunftssicheren Art und Weise geschrieben werden.
Allerdings hat diese Aktualität den Preis, dass auch die gegenwärtig aktuellen Browser ES6 noch nicht vollständig unterstützen. Dies wird im Projekt durch den Einsatz von Babelify kompensiert. Dabei handelt es sich um einen für genau dieses Problem entwickelten sogenannten Transpiler, der die in ES6 programmierten Quelltexte der VideApp wo nötig in die für aktuelle Browser durchgängig verständliche ältere Javascript-Version ES5 übersetzt und gleichzeitig auf Geschwindigkeit hin optimiert. Ändert sich der Funktionsumfang der gängigen Browser, reicht es aus, die (unveränderten) Quelltexte des Programms mit einer neueren Version von Babelify zu kompilieren, um die Software für die aktuellen Gegebenheiten zu optimieren. Damit werden die Quelltexte von den häufig wechselnden Besonderheiten der Browser entkoppelt, und bei gleichzeitiger Standardkompatibilität der Quelltexte eine größere Langlebigkeit der Software erreicht.
Um jedoch einen Transpiler wie Babelify nutzen zu können, bedarf es eines automatischen Buildsystems wie Gulp.js. Ein solches Buildsystem stellt die Infrastruktur bereit, mit der verschiedene Schritte in der Software-Entwicklung automatisiert werden können: Dateien werden kopiert, aus mehreren Bestandteilen zusammengefügt, verschoben oder auch inhaltlich überarbeitet. Für das bereits erwähnte Javascript werden so zunächst die Quelltexte aus verschiedenen Dateien der einzelnen Softwaremodule und -bibliotheken in einer Datei kombiniert, dann durch Babelify für aktuelle Browser kompiliert, und anschließend minified (minimiert, d. h. alle unnötigen Leerzeichen und sonstige „Platzverschwender“ werden entfernt) sowie uglified (Variablen- und Funktionsnamen werden durch möglichst kurze Buchstabenfolgen ersetzt), so dass eine möglichst kompakte und damit schnell via Internet übertrag- und ausführbare Datei entsteht. Ein in etwa vergleichbarer Workflow optimiert die für das Aussehen der Anwendung zuständigen CSS-Dateien, die zunächst in der moderneren und leichter wartbaren Sprache SCSS geschrieben werden, dann aber für größere Kompatibilität mit verschiedenen Browsern durch Gulp.js in traditionelles CSS umgewandelt und dabei gleichzeitig an etwaige Browser-Besonderheiten angepasst werden. Erst mit einem solchen modernen Buildsystem lassen sich die Quelltexte einer Anwendung von der Komplexität der VideApp so strukturieren, dass sie professionellen Ansprüchen an Übersichtlichkeit, Nachvollziehbarkeit und Wartbarkeit entsprechen.
Gulp.js wiederum setzt auf Node.js auf. Dabei handelt es sich um eine Plattform zur serverseitigen Ausführung von Javascript, welches ursprünglich nur für eine clientseitige Verwendung entworfen wurde. Daraus ergibt sich der große Vorteil einer Vereinheitlichung der genutzten Technologien – bestimmte Funktionen, die sowohl server- als auch clientseitig benötigt werden, müssen so nur einmal geschrieben werden, wodurch Inkonsistenzen und daraus entstehende Inkompatibilitäten vermieden werden können. Vor diesem Hintergrund ist es nachvollziehbar, dass Node.js bzw. dessen Paketmanager npm (Node Package Manager) inzwischen auch fester Bestandteil der Entwicklung von Web-Anwendungen ist. Mit npm lassen sich für das Programm benötigte Softwarebibliotheken und -komponenten verwalten und installieren, so dass die wechselseitigen Abhängigkeiten einer modularen Softwarearchitektur bequem aufgelöst werden können. Gleichzeitig dient Node.js bzw. das darauf aufsetzende Express.js als Server für die VideApp, da es als aktuell wohl populärste Plattform mit vielen gängigen Technologien kompatibel und darüber hinaus leicht erweiterbar ist.
Softwarequalität
Über Node.js werden für die Entwicklung der VideApp weitere Komponenten eingebunden, die in erster Linie die Qualität der entwickelten Software sicherstellen sollen. Dabei handelt es sich erstens um ESLint, andererseits um das damit zu erzwingende JSDoc. Beim sogenannten linting werden die Quelltexte eines Programms automatisch auf mögliche Schwachstellen oder Inkonsistenzen hin untersucht und diese entweder nach Möglichkeit direkt behoben oder dem Benutzer in Form von präzisen Fehlermeldungen aufgelistet. Dabei geht es sowohl um stilistische Fragestellungen – wann werden Quelltextzeilen wie weit eingerückt, an welcher Stelle stehen Leerzeichen usw. – als auch um tatsächliche Programmierfehler wie fehlende (oder doppelte) Variablendeklarationen (also nicht oder falsch initialisierte Programmbestandteile), im Programmablauf nicht erreichbare Codeteile und Ähnliches. Linting ist für Programmiersprachen wie C/C++ ein seit Jahrzehnten übliches Verfahren, im Bereich Javascript aber erst seit wenigen Jahren verbreitet. Der Vorteil des im Projekt genutzten ESLint (dessen Name Ecmascript Linting andeutet) ist nicht nur, dass es bereits mit dem aktuellen ES6 kompatibel ist, sondern auch, dass es damit möglich wird, JSDoc (als zweites Werkzeug zur Sicherstellung der Code-Qualität) in den Quelltexten zu erzwingen. Bei JSDoc (dessen Name an Javascript Documentation angelehnt ist) handelt es sich um eine Konvention, wie Javascript-Quelltexte mit normierten Kommentaren versehen werden müssen, um daraus vollautomatisch eine technische Dokumentation des Programms als Webseite generieren zu können.
Als drittes Werkzeug zur Sicherstellung der Softwarequalität kommt Jest zum Einsatz. Dabei handelt es sich um eine Testumgebung zur automatisierten Durchführung von sogenannten Unit Tests. Dabei werden die einzelnen Komponenten einer Software bis hinunter zu einzelnen Funktionen gezielt überprüft, indem die tatsächlichen Rückgabewerte mit den sowohl für korrekte als auch falsche Eingabewerte erwarteten Werten verglichen werden. Auf diese Weise wird verhindert, dass Modifikationen an einer Stelle der Software zu unbemerkten Änderungen im Verhalten an anderer Stelle führen – eine häufige Ursache für spätere Fehler im Programm. Gerade bei Weiterentwicklungen und Änderungen einer bestehenden Software lässt sich so die weiterhin korrekte Funktionsweise des Programms überprüfen und eine sehr zeitaufwendige Fehlersuche vermeiden. Das im Projekt genutzte Jest setzt dabei auf einer der meistverbreiteten Testumgebungen, Jasmine, auf, wurde aber für das im Projekt genutzte Frontend-Framework (einem „Baukasten“ zur Entwicklung von Benutzeroberflächen) React angepasst.
Bei dem von Facebook entwickelten, unter einer quelloffenen Lizenz verfügbaren und von Facebooks sozialem Netzwerk inhaltlich unabhängigen React handelt es sich um eine Javascript-Bibliothek zur Entwicklung moderner Webanwendungen. Der größte Konkurrent von React ist das von Google entwickelte AngularJS. Während letzteres dem verbreiteten Model-View-Controller-Paradigma folgt, zeichnet sich React in erster Linie durch seinen „unidirektionalen Datenflow“ (s. u.) aus. In herkömmlichen Webanwendungen wird Interaktivität durch sogenannte Callback-Funktionen und Listener erreicht: Wird eine bestimmte Operation abgeschlossen oder eine bestimmte Schaltfläche gedrückt, löst dies eine vordefinierte Funktion aus. Dabei ergeben sich Schwierigkeiten, wenn eine Funktion an verschiedenen Stellen ausgelöst werden kann, oder wenn eine bestimmte Information an mehreren Stellen der Anwendung angezeigt werden soll. In diesem Fall müssen sämtliche beteiligten Komponenten miteinander koordiniert werden, um Inkonsistenzen zu vermeiden. Mit wachsender Komplexität der Anwendung werden diese Querverbindungen immer unüberschaubarer und führen zu einem letztlich kaum noch wartbaren Quelltext. React verfolgt hier durch den erwähnten „unidirektionalen Datenflow“ und insbesondere in Kombination mit dem ebenfalls für die VideApp genutzten Redux einen anderen Ansatz: Jeder Zustand der Anwendung wird durch ein Javascript-Objekt beschrieben. Die einzelnen graphischen Komponenten untersuchen jeweils den für sie relevanten Teil dieses Objekts und passen ihre Darstellung selbständig diesem aktuellen Zustand an. Eine für ein etwaiges Kontextmenü zuständige Komponente wird dieses also automatisch anzeigen, wenn es der aktuelle Zustand erfordert. Der Zustand der Anwendung kann dabei nur über eine einzige, klar definierte Schnittstelle geändert werden, die dafür von allen Komponenten aus erreichbar ist. Durch diese Architektur werden die wechselseitigen Abhängigkeiten innerhalb der Software vollständig vermieden, und Daten „fließen“ immer in gleicher Weise bzw. Richtung durch die Anwendung.
Aus der Eigenschaft, den Zustand einer vollständigen React-Anwendung in einem Javascript-Objekt zu beschreiben, ergibt sich ein weiterer erheblicher Vorteil dieser Architektur: Durch ein erneutes Laden des zugehörigen Objekts kann die Anwendung in jeden beliebigen Zustand (zurück-)versetzt werden. Damit wird die in modernen Web-Anwendungen nicht immer nutzbare Browser-History verfügbar, und auch die Verlinkung eines bestimmten Zustands der Anwendung im Sinne der Referenzierbarkeit aus einer anderen Publikation heraus wird grundsätzlich möglich. Spätestens an dieser Stelle geht die Funktionalität der gewählten Softwarearchitektur übrigens über die der gegenwärtigen Edirom Online hinaus – dort sind entsprechende Möglichkeiten nur in Ansätzen und als nachträglich eingebaute Funktionalität verfügbar, hier sind sie von Grund auf und untrennbarer Bestandteil der Architektur.
Diese Zustandsobjekte werden clientseitig über die noch relativ neue LocalStorage-API des Browsers gespeichert. Dort können allerdings nur diejenigen Objekte abgelegt werden, die den quasi „vor Ort“ durch die aktive Benutzung der Software erreichten Zuständen entsprechen. Soll ein solcher Zustand aber mittels eines Links für Dritte rekonstruierbar sein, so muss das entsprechende Objekt nicht clientseitig auf dem Rechner des jeweiligen Benutzers, sondern auf einem zentralen Server gespeichert werden. Dazu wird jedes Zustandsobjekt als sogenanntes JSON-Objekt (Javascript Object Notation) an den Server der Anwendung übertragen, sofern es dort nicht bereits vorhanden ist. Über einen Hash-Wert (ein hinreichend eindeutiges Kürzel zur Identifizierung des Objekts, welches ähnlich einer Quersumme aus diesem heraus errechnet werden kann), der für die VideApp aktuell aus einer acht Zeichen langen alphanumerischen Zeichenkette besteht, lässt sich dieses Objekt dann referenzieren und bei Bedarf wieder laden.
Serverseitig stellt sich dann die Frage, wie diese Schlüssel-Wert-Paare (der Hash-Wert ist der Schlüssel, das JSON-Objekt der zugehörige Wert) gespeichert und verwaltet werden. Als erste Möglichkeit bietet sich dafür die ohnehin bereits zur Speicherung der MEI-Daten genutzte eXist-Datenbank an. Diese ist allerdings für XML-Daten optimiert, die zwar grundsätzlich eine gewisse Ähnlichkeit zu JSON haben, letztlich aber an dieser Stelle technologisch nicht vergleichbar sind. Außerdem besteht die Gefahr, diese für die eigentlichen Inhalte benötigte Datenbank mit einer Vielzahl von (relativ unwichtigen) Datenanfragen auszubremsen – mit jeder Zustandsveränderung im Browser jedes aktiven Benutzers wird mindestens eine Anfrage an diese Datenbank gestellt. Vor diesem Hintergrund erscheint es sinnvoll, eine andere, auf Geschwindigkeit im Umgang mit JSON-Daten optimierte Datenbank zu nutzen. Als solche bietet sich RethinkDB an.
Protokollierung
Mit dieser serverseitigen Speicherung jedes Anwendungszustands ergibt sich eine weitere, höchst attraktive Möglichkeit zur kontinuierlichen Überprüfung und Verbesserung der editorischen und technischen Konzepte der VideApp: In der RethinkDB lassen sich nicht nur die JSON-Objekte und ihre zugehörigen Hashes speichern, sondern auch der tatsächliche Gebrauch der Anwendung durch jeden einzelnen Benutzer. Für die Kommunikation zwischen Server und Client wird für jede Benutzer-Session, also jeden aktiven Browser-Tab, ohnehin eine eindeutige Kennung generiert, über die sichergestellt wird, dass die Ergebnisse von Datenbankanfragen an den richtigen Benutzer geleitet werden. In einem gesonderten Bereich der RethinkDB wird nun für jede solche Session ein neuer Eintrag angelegt, in dem die Abfolge der Anwendungszustände durch einen Zeitstempel und den zugehörigen Hash protokolliert wird. Eine tatsächliche Identifikation des Benutzers findet dabei nicht statt: Neben dem Verlauf werden lediglich der genutzte Browser sowie dessen bevorzugte Sprache hinterlegt. Auf diese Weise lässt sich nachvollziehen, welche Teile der Anwendung wie genutzt werden, ob also bestimmte Funktionen oder Ansichten besonders oft (oder überhaupt nicht) aufgerufen werden. Methodisch sauber aufbereitete Benutzungs- und Akzeptanzstudien lassen sich im Projekt kaum rechtfertigen; durch die genutzte Architektur werden die von solchen Studien zu erwartenden Daten hingegen automatisch und ohne weiteres Zutun generiert. Bis zu welchem Grad diese Daten dann ausgewertet werden können, wird sich im Projektverlauf zeigen müssen. Manche Informationen lassen sich dabei sehr leicht gewinnen – dazu gehört etwa, welche Sprache die Benutzer eigentlich bevorzugen, und welche sie dann tatsächlich benutzen – andere Informationen hingegen werden nicht ohne nennenswerten Aufwand zu gewinnen sein. Vor allem aber ergibt sich aus diesem Potential die Verpflichtung, diese Art der Protokollierung dem Benutzer gegenüber in einem entsprechenden Datenschutzhinweis deutlich zu machen. Dabei ist insbesondere darauf hinzuweisen, dass gerade keine Identifikation des Benutzers möglich ist, er bzw. sie also nicht durch die Anwendung überwacht wird.
Ansichten
Eine bereits mit dem ersten Prototyp eingeführte und seitdem nur geringfügig veränderte Ansicht ist die Anzeige der MEI-Codierungen als Quelltext. Dazu wird, wie auch in Edirom, der verbreitete Editor Ace genutzt. Dabei handelt es sich um einen Javascript-basierten Text-Editor, der verschiedene Datenformate unterstützt und in Webseiten bzw. Web-Anwendungen integriert werden kann. Im Rahmen der VideApp wird er dabei in einem auf das Lesen von Dokumenten beschränkten Modus („readonly“) genutzt, so dass die XML-basierten MEI-Codierungen lediglich angezeigt, aber nicht vom Benutzer modifiziert werden können. Die Vorteile eines solchen Text-Editors gegenüber einer direkten Anzeige der Codierungen sind die zusätzlich verfügbaren Funktionen: Ace etwa bietet eine Suchfunktion, die im Rahmen der VideApp genutzt wird, um gezielt die Codierung einzelner Noten etc. anspringen zu können, die z. B. im Faksimile angeklickt werden. Gleichzeitig ist Ace auf die effiziente Darstellung auch tausende Zeilen langer Codierungen hin optimiert, so dass die Lösung insgesamt deutlich effizienter ist.
Um die im Zusammenhang mit Opus 93 beschriebenen technischen Einschränkungen der Rekonstruktions-Ansicht auf Basis von Leaflet (s. o.) zu umgehen, wurde für die Weiterentwicklungen im Rahmen der VideApp nach einer anderen technischen Lösung gesucht. Die seit Beginn von Beethovens Werkstatt gemachten Fortschritte in der Weiterentwicklung der Javascript-basierten Bildanzeige-Bibliothek OpenSeadragon legten einen Wechsel von Leaflet zu OpenSeadragon (OSD) nahe. Leider ist die Dokumentation von OpenSeadragon noch immer deutlich unvollständiger bzw. unübersichtlicher als die von Leaflet, allerdings ist es (inzwischen) funktional deutlich besser geeignet, da es nicht auf Landkarten, sondern auf die Anzeige von Bildmaterial ausgelegt ist, und dabei auch mehrere Bilder in verschiedener Auflösung und mit beliebiger Skalierung nebeneinander stellen kann. Allein die Funktion einer animierten Verschiebung von Faksimileseiten wurde mit OpenSeadragon bislang noch nicht implementiert und kann daher hier nicht mit Leaflet verglichen werden – alle anderen benötigten Funktionen ließen sich bequem umsetzen, so dass sich dieser Wechsel der Anzeigebibliothek durch die nun mögliche Kombination von Digitalisaten unterschiedlicher Auflösung als sehr sinnvolle Entscheidung erwiesen hat.
Im Zuge dieser Umstellungen wurde gleichzeitig der serverseitige Umgang mit den Digitalisaten geändert. Bislang wurden diese aus manuell vorbereiteten und als solchen abgespeicherten Bildkacheln erstellt – kleine quadratische Bildausschnitte in unterschiedlichen Vergrößerungen, die es erlauben, anstatt des jeweiligen Gesamtbilds nur die benötigten Kacheln zu laden. Grundsätzlich handelt es sich dabei um eine gängige Technik, um hochauflösende Bilder dennoch hinreichend performant anzeigen zu können. Allerdings werden diese Bildkacheln i. d. R. nicht manuell vorbereitet, sondern durch einen Imageserver automatisch bereitgestellt. Diese Imageserver liefern über entsprechende URLs (Uniform Resource Locator, vereinfacht: Internet-Adressen) ganze Bilder oder Bildausschnitte in beliebiger Auflösung zurück; dabei kann es sich auch um die beschriebenen Bildkacheln handeln. Im Bereich der Digital Humanities hat sich in den letzten Jahren das IIIF-Format stark verbreitet. Bei diesem International Image Interoperability Framework handelt es sich um einen in erster Linie von Bibliotheken und Archiven entwickelten Standard, der Einzelbilder und Bildsammlungen beschreibt und eine URL-basierte API definiert, um auf diese Bilder zugreifen zu können. IIIF normiert damit die Schnittstellen unterschiedlicher Imageserver, sofern diese IIIF-kompatibel sind. Ein solch kompatibler Server ist IIPImage Server (iipsrv), der über eine zusätzliche, kommerziell vertriebene Software-Bibliothek namens Kakadu auch mit Bilddaten im Format JPEG2000 umgehen kann (eine quelloffene Alternative zu Kakadu existiert mit OpenJPEG, dessen Geschwindigkeit allerdings gerade bei hochaufgelösten Bildern aktuell noch dramatisch schlechter ist). Die Besonderheit von JPEG2000 ist, dass Software gezielt einzelne Bildbereiche in beliebiger Auflösung auslesen kann, ohne die gesamte Datei laden zu müssen – letztlich handelt es sich dabei um die Arbeitsweise, die auch ein Imageserver nutzt, hier allerdings bereits auf Ebene der Rohdaten. In Kombination ergibt sich daraus ein sehr ressourcenschonender und effizienter Workflow zur Anzeige hochauflösender Bilddaten.
Während es kostenpflichtig ist, Kakadu (als einzige kommerzielle Komponente im gesamten Technology Stack der VideApp) in eigene Programme einzubinden, kann es als Bestandteil des IIIFServer kostenfrei genutzt werden. Dabei handelt es sich um ein Paket aus iipsrv und Kakadu, welches über eine IIIF-Schnittstelle angesprochen wird. Dieses Paket wird u. a. als sogenanntes Docker-Image angeboten. Dabei wiederum handelt es sich um eine noch recht neue, inzwischen aber sehr etablierte und verbreitete Technik, um Anwendungen inkl. aller benötigten Ressourcen gebündelt als Container bereitzustellen. Diese Container lassen sich dann sehr leicht in einer definierten Umgebung installieren und nutzen. Der große Vorteil dieser Technik ist es damit, dass der Konfigurationsaufwand ebenso minimiert wird wie die Abhängigkeiten von bestimmten Laufzeitumgebungen, Serverkonfigurationen oder sonstigen technischen Gegebenheiten. Zu einem späteren Zeitpunkt des Projekts soll ggf. auch die gesamte VideApp als Docker-Image bereitgestellt werden, um so den Installationsaufwand noch weiter zu minimieren.
Beobachtungen
Es dürfte deutlich geworden sein, wie komplex das Zusammenspiel der verschiedenen Softwarekomponenten für ein Projekt wie Beethovens Werkstatt, und wie herausfordernd bereits die Auswahl dieser Komponenten ist. Oft genug lässt sich im Vorfeld einer solchen Entscheidung kaum abschätzen, wie weit die vorhandenen Möglichkeiten einer Software-Bibliothek den eigenen Anforderungen genügen können, und an welcher Stelle sich dann Hindernisse auftun, deren Lösung so aufwendig wäre, dass ihre Umsetzung zeitlich nicht mehr zu rechtfertigen ist. Diese Situation ist damit allerdings weit besser als noch vor zehn Jahren: Immerhin gibt es frei verfügbare Softwarebibliotheken, die als vorgefertigte Lösungen weite Teilbereiche der spezifischen Anforderungen abdecken können. Der Aufwand reduziert sich damit auf das „Verbinden“ dieser Versatzstücke, auf das möglichst geschickte Kombinieren von Vorhandenem und gezielte Überbrücken der aus dem spezifischen Gegenstand erwachsenden technologischen Lücken.
Diesen Aufwand aber darf man keinesfalls unterschätzen: Nur durch kontinuierliches „Beobachten“ des Marktes weit über den Tellerrand des eigenen Forschungsgebiets hinaus lassen sich die entsprechenden Möglichkeiten finden, einschätzen, erproben und ggf. integrieren. In diesem Sinne funktioniert die Prototypenentwicklung nicht anders als reguläre Forschung, die ohne Beachtung des jeweiligen Forschungsstands hinter ihren Möglichkeiten zurückbleibt. Naturgemäß handelt es sich dabei nicht um einen planbaren Aufwand – oft genug erweisen sich zunächst vielversprechende Softwarebibliotheken erst nach einer näheren Begutachtung als nicht zielführend. Auch wenn in einem solchen Fall kein unmittelbarer Nutzen entsteht, ist der damit verbundene Erkenntnisgewinn erheblich, erlaubt er in der Regel doch durch die Horizonterweiterung eine bessere und schnellere Einschätzung bei zukünftigen Entscheidungen. Auch wenn jede einzelne Softwarebibliothek für sich im Grunde trivial ist, handelt es sich bei ihrer Zusammenstellung dennoch um Grundlagenforschung im besten Sinne: Erst kontinuierliches Erproben offenbart die vorhandenen technischen Möglichkeiten, die wiederum die methodische Arbeit anregen und neue inhaltliche Perspektiven aufzeigen können. Die Herausforderung dabei ist, technologisch nicht in Abhängigkeit von einer bestimmten Komponente zu geraten: Erweist sich diese im weiteren Projektverlauf aufgrund weiterentwickelter Anforderungen als nicht (mehr) tragfähig, kann ihr Austausch massive Folgearbeiten nach sich ziehen. Vor diesem Hintergrund ist fest davon auszugehen, dass zumindest einige der hier vorgestellten Komponenten im weiteren Verlauf des Projekts ausgetauscht werden (müssen). Die beste Antwort auf diese Problematik ist die beschriebene Modularität der Software, die möglichst strenge „Kapselung“ ihrer Komponenten, durch die automatisch „Sollbruchstellen“ entstehen, welche einen nachträglichen Austausch erheblich erleichtern. Diese Schnittstellen – so der korrekte Begriff – gibt es auf verschiedenen Ebenen – zwischen Anwendung und Datenbank, zwischen Server und Client, aber auch zwischen verschiedenen Softwarekomponenten innerhalb der Anwendung. Im Folgenden soll versucht werden, das konkrete Zusammenspiel der wichtigsten Softwarekomponenten der VideApp über diese Schnittstellen zu skizzieren.
Die konkrete Umsetzung der VideApp
Technisch teilt sich die VideApp in mehrere Bereiche auf, die ihrerseits wieder aus einer Vielzahl einzelner Komponenten bestehen. An dieser Stelle soll versucht werden, die Zusammenhänge dieser Bereiche und der wichtigsten Komponenten zu verdeutlichen, und über welche Schnittstellen sie miteinander kommunizieren. Dabei soll es gerade nicht um eine technische Schnittstellen-Spezifikation gehen, wie auch dieser gesamte Text keine technische Dokumentation darstellt. Gleichwohl mag der Text als erster überblicksartiger Einstieg in die Dokumentation fungieren und dabei die wesentlichen Prinzipien vielleicht sogar übersichtlicher zusammenfassen, als es eine minutiöse Beschreibung aller Einzelaspekte (die zum jetzigen Zeitpunkt noch aussteht) vermag.
Die Grundidee der VideApp ist es, einen Rahmen bereitzustellen, in den sich beliebige Softwaremodule integrieren lassen, die jeweils eine bestimmte Ansicht bereitstellen. Um die Nachnutzbarkeit der gesamten VideApp auch über den direkten Projektkontext hinaus zu maximieren, müssen diese Softwaremodule möglichst streng gekapselt werden und dürfen nur über einige wenige, klar definierte Funktionen mit der restlichen Anwendung kommunizieren. Im Umkehrschluss bedeutet diese erwünschte Unabhängigkeit, dass nicht alles in gleicher Weise genutzt werden kann. Konkret basiert die VideApp auf der Kombination von React und Redux (s. o.), so dass ein JSON-Objekt immer den gesamten Zustand der Anwendung beschreibt. Da es sich hierbei um eine technologische Festlegung handelt, die nicht für jedes Softwaremodul nötig und sinnvoll sein muss, und im Gegenteil durchaus inkompatibel zu den modulspezifisch genutzten Softwarebibliotheken sein kann, wird der „Geltungsbereich“ von React auf die „Rahmenanwendung“ beschränkt. Dieser Bereich der VideApp baut den allgemeinen Rahmen auf, d. h. die Einstiegsseite, die Auswahl der verfügbaren Fallstudien, alle Menüs und Schaltflächen, etwaige Einstellungsseiten, die Lokalisierung für verschiedene Sprachen usw. Vor allem aber werden hier die Views verwaltet, also die Bereiche, in denen einzelne Softwaremodule ihre Inhalte darstellen können.
VideViewManager und Views
Die wichtigste Komponente in diesem Bereich ist daher der sogenannte „VideViewManager“, der als Brücke zwischen den verschiedenen Ansichtsmodulen und dem React-Teil der VideApp fungiert. Erhält er die Anfrage, dass eine bestimmte Ansicht angezeigt werden soll, führt er die nötigen Anpassungen im React-Teil der Anwendung aus und übergibt (mit mehreren Zwischenschritten, die der Übersichtlichkeit halber hier außer Acht gelassen werden sollen) die konkrete Anfrage (Request, s. u.) an einen „View“ weiter. Dieser View untersucht, ob an dieser Stelle der Anwendung zuvor die gleiche Ansicht genutzt wurde, oder ob ein Wechsel, etwa von Faksimile-Ansicht zu Transkription stattfinden muss. Im ersten Fall wird das zugehörige Softwaremodul über die neue Ansicht informiert, ohne dass innerhalb des View weitere Änderungen nötig wären. Im zweiten Fall wird dagegen das frühere Modul informiert, dass es sich bitte ordnungsgemäß schließen möge, um jederzeit einen „sauberen“ Zustand zu gewährleisten. Danach wird der Inhalt des Views gelöscht und das neue Modul angewiesen, an dieser Stelle die gewünschte Ansicht herzustellen. Wie dies geschieht, was also die einzelnen Module konkret in dem ihnen zugewiesenen Bereich der Web-Anwendung tun, erfahren weder VideViewManager noch View.
EoHub, EoModule, VideFacsimileViewer und weitere Module
Diese Module werden zentral über den sogenannten EoHub verwaltet. Alle Anfragen an die einzelnen Softwaremodule, die sich bei dieser Komponente als verfügbar „registrieren“ müssen, werden von hier aus an das jeweils geeignete Modul weitergeleitet. Dazu müssen diese Module bestimmte Schnittstellen einhalten, also Javascript-Funktionen mit einem vorgegebenen Namen und fest definierten Parametern bereitstellen, die durch andere Softwarekomponenten (wie etwa den EoHub) aufgerufen werden können und ihrerseits bei bestimmten Ereignissen bestimmte Funktionen des EoHub aufrufen. Eine der wichtigsten Funktionen ist dabei die vom EoHub bereitgestellte Funktion „confirmView“, welche ihrerseits eine gleichnamige Funktion im VideViewManager aufruft und die Funktionsinhalte so in den React-Teil der Anwendung weiterleitet. Da die Softwaremodule gerade nicht (zwingend) mit React bzw. Redux arbeiten, gibt es dort keinen vergleichbaren Automatismus, über den der jeweilige Zustand als JSON-Objekt erfasst wird. Dementsprechend lassen sich alle Benutzeraktionen innerhalb eines solchen Softwaremoduls nicht automatisch protokollieren und damit weder als Link weitergeben noch über die Browserhistory rückgängig machen. Damit wäre der ganze Nutzen dieser Funktionalität perdu: Man könnte keinen bestimmten Takt im Faksimile fokussieren, oder eine bestimmte Textschicht als Transkription referenzieren.
An dieser Stelle setzt confirmView an: Immer, wenn die Anzeige eines Softwaremoduls einen „stabilen“ Zustand erreicht (etwa nach dem Verschieben des Faksimiles oder der Auswahl einer bestimmten Textnarbe), ruft sie EoHub.confirmView auf und übergibt ein (selbstdefiniertes) JSON-Objekt, das diesen erreichten Zustand beschreibt. Im weiteren Verlauf wird dieses Objekt vom VideViewManager zusammen mit einer Referenz auf das aufrufende Modul an der entsprechenden Stelle in den Gesamtzustand der Anwendung integriert. Soll dann ein bestimmter Zustand der VideApp rekonstruiert werden, so wird dieses JSON-Objekt wieder dem ursprünglichen Modul übergeben, und es kann damit die ursprüngliche Ansicht wiederherstellen. Wie das JSON dabei strukturiert wird, ist unerheblich: Das zugehörige Softwaremodul ist die einzige Stelle der VideApp, die dieses Objekt jemals benutzen wird.
Erst mit confirmView und der streng definierten Interaktion der verschiedenen Komponenten wird also das Konzept der Reproduzierbarkeit (manchmal auch „Time Travel“ genannt) für die gesamte VideApp verfügbar. Gleichzeitig wird dabei die größtmögliche Unabhängigkeit der einzelnen Softwaremodule gewahrt, die lediglich einige wesentliche Rahmenbedingungen einhalten müssen.
Um dennoch einen möglichst einheitlichen Umgang mit den Modulen zu gewährleisten, wurde die abstrakte Javascript-Klasse des EoModule entwickelt. Dabei handelt es sich um eine Softwarekomponente, die niemals direkt im Programm aufgerufen wird. Stattdessen setzen tatsächlich nutzbare Softwaremodule wie der VideFacsimileViewer auf diesen auf, sie „erben“ dessen Funktionen und Definitionen und erweitern sie um spezifische Eigenschaften. Damit wird es möglich, mehrfach benötigte Bestandteile nur einmal zu definieren und etwaige Inkonsistenzen bei Änderungen zu vermeiden. Dennoch müssen die je spezifischen Dinge natürlich jeweils individuell programmiert werden.
Datentransport zwischen Server und Client
Eine weitere wichtige Aufgabe des EoHub ist es, eine Daten-Verbindung zum Server aufzubauen. Hierzu werden im Projekt Websockets genutzt. Diese haben gegenüber einer regulären Anfrage an den Server den Vorteil, grundsätzlich bidirektional zu arbeiten: Gibt es serverseitige Änderungen etwa an den Daten, so kann der Server eigenständig die gerade aktiven Benutzer kontaktieren und ihnen diese veränderten Daten übermitteln. Traditionell müsste ein Client regelmäßig beim Server anfragen, ob es Veränderungen gibt, und dann ggf. auf diese reagieren. Unmittelbar ergeben sich durch diese Websockets zunächst keine Vorteile; im Gegenteil ist ein automatisches Caching, durch das das erneute Herunterladen unveränderter Daten verhindert wird, mit dieser Technik nicht vorgesehen und muss eigenständig hinzugefügt werden. Wesentliche Vorteile durch den Einsatz von Websockets ergeben sich allerdings im Falle von Editor-Komponenten, die angesichts der wachsenden Datenmengen von immer größerer Komplexität mittelfristig für Beethovens Werkstatt notwendig werden. Damit wird es möglich, gezielte Editoren zu entwickeln, die bei Änderungen etwa in einer MEI-Codierung auch unmittelbar eine Transkription aktualisieren, oder auch das gemeinsame zeitgleiche Arbeiten mehrerer Mitarbeiter an einer Datei unterstützen. Entsprechende Entwicklungen sind aktuell nicht geplant, und derartige Editoren sollen keinesfalls direkt in die als Publikationsplattform gedachte VideApp einfließen; dennoch erscheint es sinnvoll, eine gemeinsame Architektur zu nutzen, die auch für diesen Bereich möglichst wenig Doppelarbeiten nach sich zieht. Websockets stellen also aus heutiger Sicht eine mittelfristige Investition in die Zukunft des Projekts dar.
Um dennoch unnötigen Datentransfer vermeiden zu können, nutzen die einzelnen Softwaremodule eine über EoModule bereitgestellte Funktion requestData, die einerseits jede clientseitige Anfrage mit einer individuellen Kennung versieht, um dann auf die entsprechend gekennzeichnete Antwort des Servers reagieren zu können, und andererseits einen vom EoHub bereitgestellten Cache nutzt, um zu überprüfen, ob die Daten überhaupt vom Server angefragt werden müssen. Bei diesem Cache handelt es sich aktuell lediglich um eine flüchtige Struktur, die mit jedem Neuladen des Browserfensters geleert wird. Da bislang übliche Techniken zur clientseitigen nicht-flüchtigen Speicherung von Daten wie etwa Cookies bei Weitem nicht den für SVG-Nachzeichnungen oder andere Daten des Projekts erforderlichen Speicherplatz bereitstellen, soll in absehbarer Zukunft für diesen Zweck IndexedDB eingesetzt werden. Dabei handelt es sich um eine von modernen Browsern bereitgestellte Struktur, die weit mehr Speicherplatz bietet und sich leicht über Javascript in Anwendungen wie die VideApp integrieren lässt. Diese architektonische Umstellung wird mit einer zentralen Änderung im EoHub für die gesamte VideApp verfügbar und ermöglicht es, bei wiederholtem Gebrauch der Anwendung größere Datenmengen lediglich ein einziges Mal laden zu müssen – die Anwendung wird spürbar schneller.
Steuerung von Modulen, Kontextmenüs und synchronisierten Ansichten
Durch die strenge Kapselung der einzelnen Softwaremodule werden Zusammenhänge zwischen diesen zunächst erschwert: Eine einzelne Ansicht, etwa die Faksimile-Ansicht, „weiß“ nicht, welche weiteren Ansichten es gibt, und kann dementsprechend nicht ohne weiteres Bezug darauf nehmen und etwa Zugriff in eine Transkription oder zur XML-Codierung anbieten. Gleichwohl sind natürlich gerade diese Querbezüge unverzichtbar, um die Inhalte von Beethovens Werkstatt in allen Facetten erfassen zu können. Aus diesem Grund werden derartige Querbezüge unter Einbeziehung der Gesamtarchitektur umgesetzt.
Grundsätzlich werden zur Anzeige eines bestimmten Objekts in einer bestimmten Ansicht immer Requests genutzt. Dabei handelt es sich um im Projekt entwickelte, immer gleich aufgebaute JSON-Objekte, welche die gewünschte Ansicht beschreiben. Dazu wird zunächst die Art des gewünschten Objekts festgelegt, also ob es sich um einen Takt, eine Seite oder eine Textschicht handelt. Weiterhin wird die konkrete XML-ID des Objekts übergeben, mit der dieses identifiziert wird. Die weiteren Angaben beinhalten die Art der gewünschten Perspektive, also ob das gesuchte Objekt als Faksimile, Transkription, im XML oder sonstiges angezeigt werden sollen. Aktuell ist nur diese Form der Interaktion vorgesehen: „Anzeigen“. Durch die dennoch explizit in jedem Request enthaltene Information lassen sich später bei gleichbleibendem „Kommunikationsprotokoll“ leicht auch andere Operationen anfordern, etwa „Ändern“ oder „Löschen“. Damit sind auch in diesem Protokoll die Grundlagen für einen späteren Editor gelegt.
Jedes Softwaremodul definiert für sich eine Liste mit unterstützten Requests. Sollen nun aus einem Softwaremodul heraus andere Module aufgerufen, also etwa in einem Kontextmenü alle weiteren verfügbaren Ansichten auf eine aktuell in der Transkriptions-Ansicht dargestellte Note aufgelistet werden, so wird zunächst über den EoHub eine Gesamtliste aller von den verfügbaren Softwaremodulen unterstützten Requests erstellt, die der gewünschten Objektart entsprechen – hier also einer Note, und eine andere Perspektive bieten als das aktuelle Modul – im Beispiel also alles außer Transkriptionen. Diese „Musterrequests“ werden nun mit der ID des gewünschten Objekts angereichert und über EoHub an den VideViewManager übergeben. Mit der dort verfügbaren Information zu den gegenwärtigen Ansichtseinstellungen der VideApp wird über React ein Kontextmenü geöffnet, welches für jeden übergebenen Request einen Eintrag enthält. Wird einer dieser Einträge vom Benutzer ausgewählt, so wird über View.react.js der entsprechende Request an das erforderliche Softwaremodul weitergereicht und die gewünschte Anzeige hergestellt.
Werden mit der VideApp mehrere Ansichten über- bzw. nebeneinander angezeigt, so lassen sich diese synchronisieren. Voraussetzung dafür ist, dass auch zur Navigation innerhalb eines Softwaremoduls – also etwa dem Anspringen eines bestimmten Taktes in der Faksimile-Ansicht – Requests genutzt werden, die zwar letztlich vom gleichen Modul umgesetzt werden, vorher aber über EoHub und VideViewManager zu View.react.js geleitet werden. Dort wird der ankommende Request zunächst an das ursprüngliche Softwaremodul durchgereicht. Hat der Benutzer die Synchronisierung der Ansichten aktiviert, so wird nun zusätzlich eine Kopie des Requests in entsprechend modifizierter Form an das zweite angezeigte Softwaremodul weitergereicht, so dass dieses die gewünschte zweite Perspektive auf das aktuelle Objekt umsetzen kann.
Serverseitige Architektur
Wie bereits erwähnt, wird als grundsätzlicher Server Express.js benutzt. Die erwähnten Datenverbindungen mittels Websockets werden an dieser Stelle über ein zusätzliches Javascript-Programm (socket.io) bereitgestellt. Sämtliche über diese Schnittstellen eintreffenden Anfragen werden hier umgewandelt in Datenbankanfragen, die über eine definierte REST-Schnittstelle an die eXist-Datenbank weitergereicht werden. Bei einer solchen Schnittstelle handelt es sich vereinfacht um eine Festlegung, dass eine Anfrage an eine bestimmte Internetadresse ein erwartbares Ergebnis liefert. Dabei kann es sich um Internetseiten handeln, aber auch, wie in diesem Fall, um bestimmte Datenpakete im XML– oder JSON-Format. Als Vorteil ergibt sich daraus, dass auch hier wieder eine „Sollbruchstelle“ entsteht: Es ist denkbar einfach, eXist-DB durch eine beliebige andere Datenbank auszutauschen – solange diese die bisherige REST-Schnittstelle in gleicher Weise bereitstellt, also auf gleichartige Anfragen in gleicher Weise antwortet. Damit werden einerseits mögliche Änderungen in der Zukunft wesentlich erleichtert, andererseits lässt sich die Anwendung so leichter in abweichende Software-Umgebungen anderer Projekte integrieren, also leichter nachnutzen.
Durch die Übersetzung der über Websockets eingehenden Datenanfragen auf REST-Anfragen gibt es an dieser Stelle zusätzlich die Möglichkeit, ein serverseitiges Caching zu implementieren: Während viele Anfragen sehr individuell sind, gibt es einige Anfragen, die jeder Benutzer stellen dürfte, deren immer gleiche Antwort innerhalb der eXist-Datenbank aber relativ aufwendige (und damit zeitraubende) Berechnungen erfordern. Dazu gehört etwa, aus den vollständigen MEI-Codierungen eines Fallbeispiels eine einzelne Variante zu extrahieren, die dann clientseitig mit Verovio gerendert werden soll. Hier böte es sich mittelfristig an, die Ergebnisse dieser Berechnungen zwischenzuspeichern, so dass diese bei einer gleichen Anfrage einfach in gleicher Weise wieder beantwortet werden können. Ein solcher Mechanismus ist grundsätzlich auch innerhalb von eXist zu realisieren; durch die gewählte Server-Architektur gibt es nun aber eine weitere Möglichkeit, wo ein solches Caching stattfinden kann, so dass aus mehreren Optionen die effizienteste ausgewählt werden kann. Diese Alternativen sollen daher zumindest mittelfristig untersucht werden.
Die (gegenwärtig) letzte Schnittstelle des Servers ist die Anbindung an RethinkDB. Dort werden sämtliche Anwendungszustände abgelegt, sowie der Verlauf der Operationen einzelner Benutzer in anonymer Form protokolliert (s. o.). Die Kommunikation mit einzelnen Browsern funktioniert dabei wiederum über die bestehenden Websocket-Verbindungen. Auch hier besteht die sehr einfache Möglichkeit, bei Bedarf auf andere Datenbanken zurückzugreifen, bzw. in Zukunft eine Schnittstelle zu schaffen, um die gesammelten Nutzungsdaten systematisch auszuwerten und anhand der gewonnenen Erkenntnisse die VideApp selbst zu optimieren.
Fazit
Der vorliegende Text ist eine Zwischenbilanz: Es ist davon auszugehen, dass im weiteren Projektverlauf Änderungen vorgenommen werden (müssen), Änderungen sowohl an der Architektur der VideApp als auch den genutzten Technologien. Angesichts der Geschwindigkeit der technischen Entwicklungen in diesem Bereich und vor dem Hintergrund der Laufzeit eines Akademieprojekts lässt sich dies nicht umgehen. Im Gegenteil muss dieser Umstand als Vorteil verstanden werden, der es erlaubt, kontinuierlich nach neuen Lösungen, Ansätzen und Herangehensweisen zu suchen und Veraltetes zu ersetzen. Dabei handelt es sich um Grundlagenforschung im eigentlichen Wortsinn. Diese Grundlagenforschung muss sich die Zeit zugestehen, auch erst im Nachhinein als solche erkennbare Irrwege zu gehen. Oft genug ergibt sich aus diesen Irrwegen die Inspiration, die letztlich zu neuen methodischen Erkenntnissen führt und das Projekt damit auch inhaltlich voranbringt. Damit wird aus dem „Dreisprung“ Erkenntnisgewinn – Erkenntnismodellierung – Erkenntnisvermittlung ein Kreislauf: Editorische Erkenntnisse werden in die strikte Terminologie einer Codierung überführt und als (MEI-)Daten modelliert, diese Codierungen werden dann mittels Software angezeigt und ausgewertet. Durch die Auswertung der Daten werden mitunter vorher unbeachtete Querbezüge oder Perspektiven sichtbar (hier ist z. B. die Rekonstruktionsansicht der VideApp zu nennen) oder methodisch Unausgegorenes aufgedeckt (dies betrifft z. B. die ersten Versuche hinsichtlich einer Invarianz-Einfärbung anhand von Opus 59, 3), was zu einer Präzisierung der Methodik verhilft und neue Impulse für die editorische Arbeit setzt. In den Digital Humanities ist die Bedeutung von Daten bzw. Datenmodellierung weitgehend unbestritten. Weit weniger Beachtung hat die Softwareenwicklung erfahren: Allzu oft wurde sie lediglich als Mittel zum Zweck wahrgenommen, als reine Dienstleistung (vgl. etwa Simon Hettrick: Research Software Sustainability: Report on a Knowledge Exchange Workshop, o.O. 2016, S. 8). Gerade am Beispiel von Beethovens Werkstatt wird aber deutlich, welche wissenschaftliche Komplexität gerade auch in der Softwareentwicklung als gleichberechtigter Aspekt des Gesamtprojekts liegt: Natürlich ist die Implementierung einer einzelnen Javascript-Bibliothek aus Sicht der Informatik trivial. Die Herausforderung liegt darin, bestehende Komponenten, die in der Regel für andere Zwecke entwickelt wurden, so zu verweben, dass sie zielgerichtet und sachdienlich ein bestimmtes methodisches Konzept herausarbeiten, hinterfragen oder vermitteln. Gerade dieser Schritt erfordert eine enge Abstimmung mit den fachwissenschaftlichen Anteilen innerhalb Projekts – ohne ein tiefgehendes Verständnis der dort verorteten Methoden und Konzepte kann aus dem „Dreisprung“ gerade kein Kreislauf entstehen, die einzelnen Projektbereiche bleiben mehr oder weniger unvermittelt nebeneinander stehen, ohne sich im Dialog gegenseitig stimulieren zu können. Dies lässt sich nur vermeiden, indem Softwareentwicklung als eigenständiger und gleichwertiger Bestandteil der Forschungsarbeit, und gerade nicht als nachgeordnete Dienstleistung erkannt wird. Umso wichtiger erscheint es, die Bedeutung, aber auch die Herausforderungen von Softwareentwicklung offen zu kommunizieren und durch entsprechende Ressourcen zu unterstützen. Letztlich lässt sich nur auf diese Weise eine so fruchtbare Symbiose zu tatsächlichen Digital Humanities erreichen wie im Falle von Beethovens Werkstatt.
Johannes Kepper