
zurück zum Inhaltsverzeichnis
Expertengespräch zur genetischen Textkritik im Bereich Musik
Das Datenmodell von Beethovens Werkstatt
Die grundsätzliche Frage innerhalb des Projektes Beethovens Werkstatt ist die nach dem Verhältnis von Codierung und Faksimile. Es kann durchaus festgehalten werden, dass die Leistungsfähigkeit bzw. Aussagekraft der Codierung geringer ist, je unsicherer oder offener der Befund im Faksimile ist. Dies soll im Folgenden verdeutlicht und anhand eines Vergleichs mit dem Datenmodell der Text Encoding Initiative (TEI) sowie einiger Beispiele dokumentiert werden.
Innerhalb der TEI gibt es seit 2011 ein Modell zur Codierung genetischer Prozesse, in dem zwei Codierungen parallel erstellt werden: Eine des Textes, und eine des Dokuments (im Sinne einer diplomatischen Transkription). Beide werden dann durch Querverweise miteinander in Bezug gesetzt. Im Grunde ist dies als Möglichkeit zu verstehen, den Text sowohl in inhaltliche als auch graphische Aspekte betonende Hierarchien einzupassen. Das eigentliche Markup bleibt dabei in beiden Codierungen annähernd gleich, jedoch verändern sich die Strukturen der Auszeichnung. Damit wird es einerseits möglich, die Einheiten Dokument und Text in einer digitalen textgenetischen Edition sauber zu trennen, andererseits entsteht ein hohes Maß an Redundanz in der Codierung, die aufgrund der vielen Verweise nur schwer zu pflegen ist.
Unsere Codierung von Musik mit den Mitteln der Music Encoding Initiative (MEI) operiert in anderer Weise als das beschriebene Modell der TEI; Beethovens Werkstatt versucht, ein MEI-Datenmodell zu entwickeln, welches Dokument und Text zeitgleich adressiert.
Ein direkter Vergleich der Modelle von TEI und MEI zeigt einen gravierenden Unterschied in der Auszeichnung von Inhalten. Denn durch das Ausblenden des Markups eines codierten Ausschnittes bleibt auf TEI-Seite der tatsächliche Inhalt des Textes stehen, auf MEI-Seite verschwinden jedoch alle inhaltlichen Informationen zur Musik. Bezeichnenderweise bleibt dort allein die Textunterlegung stehen (vgl. Abb.1).
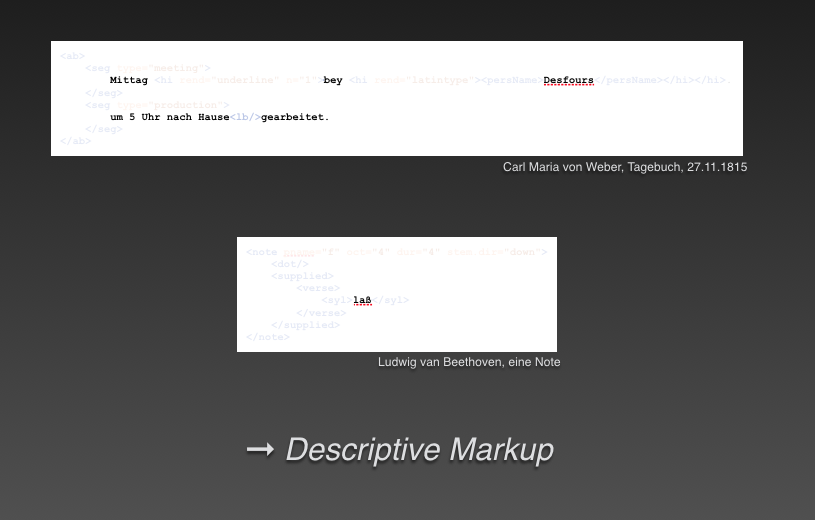
Eine Codierung innerhalb der Literaturwissenschaften zielt also auf das Dokument, den Befund ab („documentary transcript“) und erlaubt eine diplomatische Rekonstruktion, während eine zweite Codierung auf den Text abzielt und inhaltlich ausgerichtet ist („textual transcript“) (vgl. Abb. 2).1
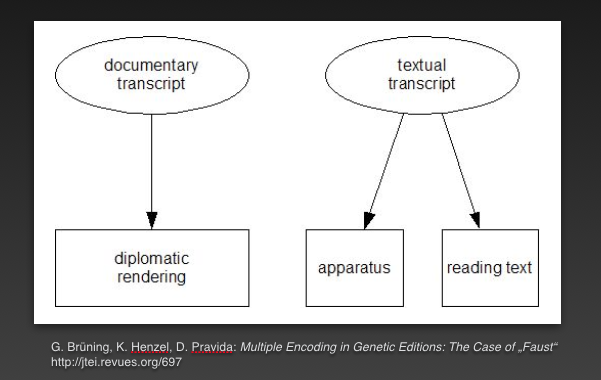
Hier werden demnach Buchstaben und Zeichen linguistischen Einheiten gegenübergestellt, welche aber mit demselben Zeichenvorrat erfasst werden und die prozessbeschreibenden Elemente, die darin enthalten sind, nicht in Gänze verdeutlichen können.
Im Bereich der Musik dient die Auszeichnungssprache XML jedoch vielmehr der Beschreibung von Einzelobjekten und Phänomenen, anstatt einen grundsätzlich bestehenden Text auszuzeichnen und anzureichern. Man spricht daher auch von „beschreibendem“ oder „descriptive markup“.
Diese Art der Codierung bringt gerade bei der Erfassung von skizzenhafter Notation — welche unter anderem als Cue staff-Notate relativ häufig in Beethovens Werken vorkommen — große Herausforderungen mit sich, denn dort scheint eine möglichst offene und interpretationsfreie Codierung des Inhaltes nahezu unmöglich zu sein. In der Literaturwissenschaft werden selbst in Skizzen zum Beispiel vollständige Buchstaben als kleinste sinnvolle Einheit erfasst. In der Musik kann dies nicht gelten, da es für eine Note sozusagen keine „digitale Entsprechung“ auf Codierungsseite gibt. Ein Melodieverlauf kann etwa nur durch Notenköpfe und -hälse skizziert werden, ohne dass dies bereits eine rhythmische Abfolge festlegt. Diese mangelnde rhythmische Festlegung ist aber am einzelnen Notenzeichen nicht ersichtlich. Eine Skizze ist also unter Umständen nicht als solche zu erkennen und verleitet zu Deutungen, die vom Befund des Faksimiles nur scheinbar gedeckt werden.
In der Musik gilt es somit, das zentrale Problem der Unvollständigkeit des Befundes (wie zum Beispiel eine skizzenhafte Notation) möglichst ohne Interpretation des Editors in der Codierung umzusetzen.
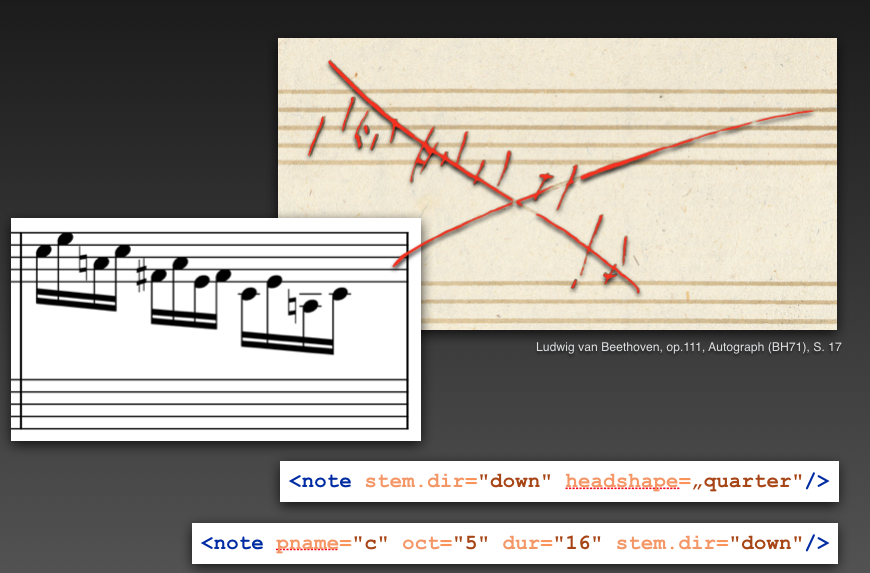
Ein skizzenhafter Melodieverlauf, wie in der Abbildung aus Beethovens op. 111, lässt kaum Rückschlüsse auf deren Rhythmik zu: In der Abbildung ist ein Lauf von Noten zu sehen, der skriptural nur aus Notenköpfen (im weitesten Sinne) und Hälsen besteht.

Würde an dieser Stelle ausschließlich der Befund betrachtet, müssten die Noten mit den Attributen „Notenhals nach unten“ (@stem.dir=„down“) und „Notenkopf in der Form einer Viertel“ (@head.shape=„quarter“) beschrieben werden.
An dieser Stelle geht das Codierungsmodell des Projekts in den analogen und digitalen Transkriptionen über den Befund hinaus und bietet eine bewusste Interpretation an.
Also sehen die beschriebenen Noten im Codierungsmodell völlig anders aus, da sie im Markup direkt als Sechzehntel interpretiert werden (vgl. Abb. 4).
Die Frage ist nun aber, wie neben dieser Deutung der Befund der Quelle wiedergegeben werden kann, wenn eine klare Trennung zwischen Dokument und Text angestrebt wird. Während die inhaltliche und interpretatorische Erfassung auf Seiten der MEI-Codierung geschieht, werden alle graphischen Zeichen und Elemente des Faksimiles nachgezeichnet und in SVG-Shapes erfasst.
Dies geschieht am besten durch die absolut getreue Wiedergabe jedes einzelnen Zeichens des Faksimiles. Dafür werden sämtliche Zeichen auf Ebene der einzelnen Striche (zur Zeit manuell) nachgemalt. Natürlich enthält bereits dieser Schritt ein gewisses Maß an Interpretation, aber auch das Faksimile selbst ist ein subjektives Abbild, doch wird hiermit das höchstmögliche Maß an Objektivität gewährleistet.
Diese manuelle Markierung der einzelnen Schreibspuren dauert etwa 8 bis 12 Stunden pro Seite, wobei sogenannte Pfade entstehen, welche die genaue Form jeder Schreibspur auf Ebene einzelner Striche beschreiben. Diese Vektoren werden als SVG-Datei generiert und gespeichert. SVG steht für Scalable Vector Graphics und meint ein weiteres XML-Format, welches für beliebige Grafikdateien genutzt wird. Der wesentliche Vorteil von SVG ist, dass es sich dabei um ein gegenüber den Inhalten agnostisches Grafikformat handelt, welches sich gerade keiner musikalischen Terminologie bedient und damit auch nicht zu einer Interpretation nötigt. Eine SVG-Shape ist lediglich eine inhaltsleere Beschreibung einer aus technischer Sicht beliebigen Form, die erst in der MEI-Codierung durch die Verknüpfung mit einem musikalischen Zeichen als solche erkannt wird.

Für unser Datenmodell ergibt sich daraus folgende Dreiteilung:
Ausgehend vom Faksimile werden Einzelzeichen als SVG identifiziert und können als Befund bezeichnet werden. Darauf aufbauend werden MEI-Codierungen erstellt und angeboten, welche eine explizite Deutung des Befunds wiedergeben, d. h. auch jenseits von (als solchen gekennzeichneten) Herausgeberzusätzen wird hier den Einzelzeichen eine Bedeutung zugewiesen. Durch die Verknüpfung von MEI und SVG lässt sich jede Deutung auf den zugrundeliegenden Befund zurückführen, was zur größtmöglichen Transparenz führt.
Vergleicht man dieses Modell nun mit dem eingangs erwähnten Ansatz der TEI, so zeigt sich auch hier eine grundsätzliche Zweiteilung der Codierung, welche die Kategorien „Dokument“ und „Text“ separat adressiert. Allerdings werden dabei bewusst zwei unterschiedliche Beschreibungssprachen genutzt: Während die Transkription des Textes als bewusste Deutung eine inhaltliche Codierung mittels MEI nutzt, wird das Dokument als rein graphisches, d. h. inhaltsagnostisches SVG erfasst. Obwohl gerade bei sich überlagernden Zeichen bereits die Festlegung ihrer Konturen eine Interpretation, d. h. Deutung ist, wird durch diesen bewussten Verzicht auf eine inhaltlich-terminologische Festlegung größtmögliche Objektivität in der Erfassung des Befunds erreicht.
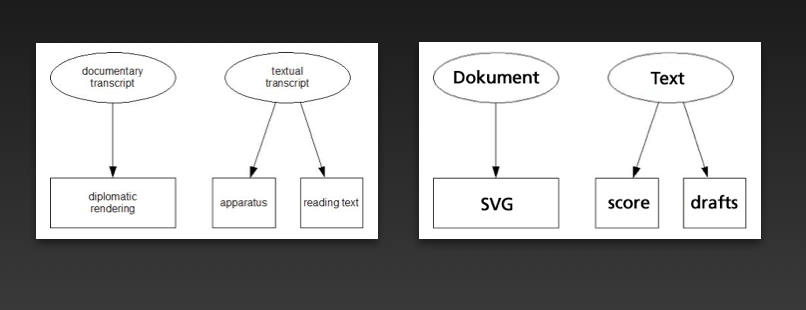
Die in Abb. 6 erkennbare Aufteilung der Codierung des Textes folgt dabei ebenfalls einer anderen Motivation als im Modell der TEI.
Welche Möglichkeiten ergeben sich nun aus den untereinander engmaschig vernetzten Komponenten Digitales Faksimile, SVG-Codierung des Befunds und einer in MEI erfassten Deutung desselben? Zunächst wird es möglich, die MEI-Codierungen wieder in einen Notentext (und damit in einen les- bzw. nutzbaren Zustand) zu überführen. Dies geschieht mit Hilfe von Verovio, einer unter Federführung von Laurent Pugin entwickelten Softwarekomponente zum automatisierten Satz (Rendering) von digital codierten Noten. Wenngleich es gerade in der Anfangszeit von Beethovens Werkstatt noch einige funktionale Einschränkungen gab, so ist die Entwicklungsgeschwindigkeit dieses erst 2014 begonnenen, in der MEI-Community aber vielfach eingesetzten Werkzeugs mindestens ebenso beeindruckend wie die bereits erreichte Darstellungsqualität. Das überzeugendste Argument für Verovio aus Sicht von Beethovens Werkstatt ist aber die enge Verzahnung der gesetzten Noten mit der zugrundeliegenden MEI-Codierung: Jede einzelne Note oder Pause, jeder Akkord, Bogen oder sonstige Bestandteil des Notenbilds behält intern eine Referenz auf das entsprechende Element in MEI. Damit fügt sich das Rendering als vierte, nach Benutzervorgaben dynamisch erzeugte Komponente neben Digitalisat, SVG- und MEI-Codierung ein. Aus diesen nun vier Grundbestandteilen werden die verschiedenen Software-Prototypen erstellt, mit denen im Projekt verschiedene Möglichkeiten zur möglichst intuitiven Vermittlung von Textgenese erprobt werden.
In einem ersten Schritt lassen sich die verschiedenen, vom Herausgeber erkannten Varianten im Digitalisat graphisch hervorheben, indem die entsprechenden SVG-Shapes in einer semitransparenten Einfärbung über das Digitalisat geblendet werden. Dadurch kann der Benutzer unmittelbar nachvollziehen, welche graphischen Zeichen eine Variante konstituieren, eine räumliche Orientierung wird auch bei Randnotaten oder sich teilweise überlagernden Varianten leicht möglich. Die Varianten selbst sind Bestandteil des Werktextes und dementsprechend in den MEI-Codierungen erfasst. Alle zugehörigen Noten etc. haben eine Verknüpfung zu den ihnen zugrunde liegenden Zeichen (die ja als SVG-Shapes vorliegen). Diese wiederum werden mit dem Digitalisat der Handschrift in Bezug gesetzt, so dass für den Benutzer nicht das nachgemalte Objekt im Vordergrund steht, sondern dieses lediglich als Hervorhebung auf bzw. in Beethovens Handschrift wahrgenommen wird. Schon für eine „einfache“ Einfärbung der Varianten werden also drei der vier beschriebenen Komponenten genutzt. Mit der vierten Komponente, dem Rendering der MEI-Codierungen, wird es darüber hinaus möglich, die in den einzelnen Varianten vorgefundenen Texte als „sauberen“ Notentext darzustellen. Damit wird die gerade bei Überarbeitungsprozessen mitunter nur sehr schwer lesbare Handschrift Beethovens auch für Nicht-Spezialisten erheblich leichter zugänglich, ein direkter Vergleich vom Befund der Handschrift mit der Deutung des Editors möglich. Die bereits erwähnte Rückbindung des „gerenderten“ Notentextes an die Codierung erlaubt es dabei, nicht nur die Gesamtvariante in Originalhandschrift und Transkription zu vergleichen, sondern auch gezielt einzelne Zeichen durch Anklicken auf einer der beiden „Seiten“ auch auf der jeweils anderen hervorzuheben. Dadurch wird die editorische Arbeit vollständig transparent – jedes noch so kleine Detail lässt sich am Digitalisat nachvollziehen und kritisch hinterfragen. Auch die alles verbindende MEI-Codierung lässt sich von allen genannten Punkten aus an der jeweils relevanten Stelle öffnen – letztlich ist die Codierung die Edition, alles andere sind lediglich abgeleitete Darstellungsweisen dieser extrem formalisierten, terminologisch strikten, aber nur bedingt direkt lesbaren Beschreibung. Da aber die darauf aufsetzenden Darstellungsmöglichkeiten ihrerseits fehlerhaft sein können, ist es von zentraler Bedeutung, auch diese „Rohform“ der Edition frei zugänglich zu machen, um damit auch für diesen technischen Bereich Transparenz herzustellen. Die in Beethovens Werkstatt entwickelten Prototypen und Beispiel-Editionen erfüllen damit den wissenschaftlichen Ausgaben eigenen Anspruch auf Nachvollziehbarkeit in bislang ungekannter Weise.
Aber auch neuartige Vermittlungsformen, die in besonderer Weise textgenetische Zusammenhänge und Prozesse verdeutlichen können, werden durch das Datenmodell von Beethovens Werkstatt ermöglicht. Das bereits im Beitrag von Susanne Cox vorgestellte Konzept der Invarianz etwa basiert technisch auf der Verbindung zwischen den mit Verovio dargestellten Transkriptionen und den zugrundeliegenden MEI-Codierungen. Letztere werden dazu um die spezifischen Informationen zur Abhängigkeit der Noten verschiedener Varianten ergänzt. 2
Eine weitere, im Rahmen der Arbeiten an Beethovens Lied op. 75,2 konzipierte und erstmals umgesetzte Präsentationsform ist die sogenannte „Rekonstruktionsansicht“. Diese nutzt die nachgezeichneten SVG-Shapes der Noten- und sonstigen Zeichen, die Schreibschicht für Schreibschicht auf ihrer ebenfalls nachgezeichneten leeren Notenseite eingeblendet werden können. Solche Darstellungen früherer Zustände von Manuskripten, also letztlich Zwischenstadien im Beschreibungsprozess, gab es bereits in früheren Publikationen. Allerdings handelt es sich dabei durchgängig um manuell erstellte Bilddateien. Diese erfüllen zunächst durchaus ihren Zweck – sie vermitteln dem Benutzer anschaulich, wie ein Manuskript zu einem bestimmten Zeitpunkt mutmaßlich aussah. Allerdings bleiben sie letztlich wie eine gedruckte Ausgabe statisch und ohne Interaktion. Es ist gerade nicht möglich, einzelne Zeichen gezielt bis in die Codierung zu verfolgen und ihre Deutung kritisch zu hinterfragen. Auch für den Herausgeber, in diesem Fall also den Bildbearbeiter, bleibt es beim alten Paradigma, sich auf eine Deutung festlegen zu müssen. 3
Beethovens Werkstatt versucht demgegenüber, keine Sicherheit vorzuspiegeln, wo der Herausgeber nicht zuverlässig entscheiden kann, in welcher Reihenfolge bestimmte Schreibprozesse erfolgt sind. Ein in den Digital Humanities vielbeachtetes Beispiel, Elena Pierazzos „Proust Prototype“, versucht diese Unsicherheit durch eine Einfärbung der jeweils überblendeten Transkription zu verdeutlichen (vgl. Abb. 7). Dabei wird allerdings lediglich die Unsicherheit als solche vermittelt; welche Alternativen zur gewählten Reihenfolge bestehen, ist hingegen nicht ersichtlich.

In der Rekonstruktionsansicht von Beethovens Werkstatt hingegen werden bewusst mehrere Möglichkeiten angeboten, wenn aus editorischer Sicht keine hinreichend sichere Aussage zur Reihenfolge getroffen werden kann. Damit kann der Benutzer verschiedene Möglichkeiten rekonstruieren und eigenständig auf ihre Plausibilität hin überprüfen (vgl. Abb. 8).

Auf diese Weise wird also der Erkenntnisstand des Herausgebers sehr viel korrekter wiedergegeben, als dies mit anderen Lösungen möglich wäre: Als Benutzer kann man nicht nur das Beschreiben der Seite Schritt für Schritt „mitverfolgen“, man kann auch sehen, welche Konsequenzen denkbare unterschiedliche Abfolgen haben. In traditionellen Ausgaben ließen sich diese Informationen bzw. Alternativen lediglich verbal vermitteln – und damit i. d. R. deutlich schlechter nachvollziehen.
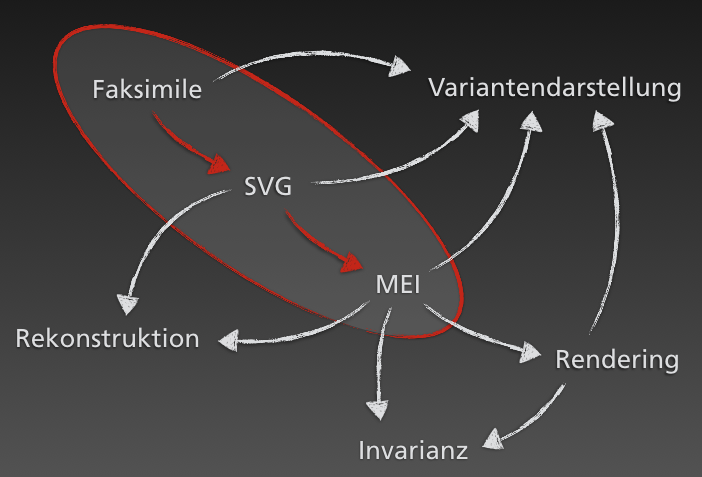
Auch diese innovative Darstellungsform basiert, ebenso wie das Konzept der Invarianz, auf den bereits erwähnten Komponenten des projekteigenen Datenmodells (vgl. Abb. 9). In diesem nimmt MEI die zentrale Rolle ein – ohne die vielfältigen Verknüpfungs- und Beschreibungsmöglichkeiten dieses Datenformats wären digitale Editionen nicht in vergleichbarer Komplexität bzw. Interaktivität möglich. Gleichzeitig wird deutlich, dass trotz des sehr spezifischen Gebrauchs dieses Formats eine Rückkopplung an allgemeine Werkzeuge aus der MEI-Community, insbesondere Verovio, sehr gut möglich ist und sogar wesentlich zum Erfolg des Projekts beiträgt. Damit nimmt das Datenmodell eine sehr zentrale Rolle in Beethovens Werkstatt ein: Es erfasst alle editorisch-inhaltlichen Erkenntnisse des Projekts in formalisierter Form, dient als Grundlage sämtlicher Darstellungs- und Publikationsformen, und stellt gleichzeitig die technische Verbindung zu anderen Projekten her.